Privacy and Commercial and Social Interests
Readings
Baase Chapter 2.
Privacy from others
Internet Search Records
Webcam Spying
Pennsylvania School Laptops
Facebook
News Feeds
Advertising
Facial
Recognition at Facebook
Privacy Settings
Credit Bureaus and Credit-like Information
Facial Recognition
Tinder
Managing your privacy
Public Records
Theories
Workplace Email
Smyth v Pillsbury
Advertising
Cookies
Location data
Target
RFID
SSNs
Price Discrimination
Google Buzz
Google Buzz was google's first attempt at a social-networking site, back in
~2009[?]. When it was first introduced, your top gmail/gchat contacts were
made public as "friends", even though the existence of your correspondence
may have been very private. For many, the issue isn't so much that yet
another social-networking site made a privacy-related goof, but that it was
Google, which has so much private
information already. Google has the entire email history for many people,
and the entire search history for many others. The Google Buzz incident can
be interpreted as an indication that, despite having so much personal
information, Google is sometimes "clueless" about privacy. At the very
least, Google used personal data without authorization.
For many people, though, the biggest issue isn't privacy per se, but the
fact that their "google profile" overnight became their buzz page, without
so much as notification.
See http://www.nytimes.com/2010/02/15/technology/internet/15google.html.
Or http://searchengineland.com/how-google-buzz-hijacks-your-google-profile-36693.
Google search data
Consider the following site (which is an advertisement for duckduckgo.com):
http://donttrack.us/
Some points:
- Every site you go to, no
matter how you found it, has your IP address (unless you attempt to hide
that); this is not new.
- When you click on a link to a site that appears in a google search,
the site gets your search term from google. You can also copy/paste the
site URL, which usually avoids this.
- third-party advertisers track you with cookies and whatever other data
(eg search data) they can obtain.
- While Google can sell your search data to others, they are under
considerable marketplace pressure not to. This does not, however, apply
to those third-party advertisers.
To be fair, Google famously resisted a US subpoena for a large sample of
"anonymized" search records, even before the AOL search leak (below) when it
became clear to everyone that these were a bad idea.
AOL search leak, 2006
Baase 4e pp 50-51 / 5e p 56: search-query data: Google case, AOL leak.
In August 2006, an AOL scientist released 20,000,000 queries from ~650,000
people. The data was supposedly "anonymized", and did not include IP
addresses, but MANY of the people involved could be individually identified,
because they:
- searched for their own name
- searched for their car, town, neighborhood, etc
Many people also searched for medical issues.
Wikipedia: "AOL_search_data_scandal"
Thelma Arnold was one of those whose searches were made public. The New
York Times tracked her down; she agreed to allow her name to be used. See
www.nytimes.com/2006/08/09/technology/09aol.html.
As of 2018 the actual data can still be found on the Internet.
See: www.techcrunch.com/2006/08/06/aol-proudly-releases-massive-amounts-of-user-search-data
What would make search data sufficiently anonymous?
Question: Is it ethical to use the actual
AOL data in research? What guidelines should be in place?
Are there other ways to get legitimate search data for sociological
research?
How much of your google-search history is stored on your computer? Where is
it?
What constitutes "consent" to a privacy policy?
Are these binding? (Probably yes, legally, though that is still being
debated)
Have we in any way consented to having our search data released?
Search records and computer forensics
In 2002, Justin Barber was found shot four times on a
beach in Florida. None of his injuries were serious. His wife April,
however, had been shot dead. Barber described the event as an attempted
robbery.
There were some other factors though:
- Barber had recently taken out a large life-insurance policy on his
wife
- Barber was having an affair
- Barber was heavily in debt
- April Barber's family was sure Justin did it
Police searched Barber's computer for evidence of past Google searches. They
apparently did not contact Google
directly. Barber had searched for information on gunshot wounds,
specifically to the chest, and under what circumstances they were less
serious. Barber was convicted.
More at:
http://news.cnet.com/8301-13578_3-10150669-38.html
Lee Harbert:
Harbert's vehicle struck and killed Gurdeep Kaur in 2005. Harbert fled the
scene. When arrested later, his defense was that he thought he had hit a
deer. But his on-computer searches were for
"auto glass reporting requirements to law enforcement"
"auto glass, Las Vegas" (the crime was in California)
"auto theft"
He also searched for information on the accident itself. Harbert too was
convicted.
more at http://news.cnet.com/8301-13578_3-10143275-38.html
Wendi Mae Davidson
Police found her husband's body in a pond at the ranch where Davidson
boarded her horse. Police found the ranch itself by attaching a GPS recorder
to her car. Davidson also used an online search engine to search for the
phrase "decomposition of a body in water".
More at http://news.cnet.com/Police-Blotter-Murderer-nabbed-via-tracking,-Web-search/2100-7348_3-6234678.html
Neil Entwistle
Entwistle's wife Rachel and daughter Lillian were found shot to death in
January 2006. Neil had departed for England. Besides the flight, there was
other physical evidence linking him to the murders. However, there was also
the Google searches:
A search of Entwistle's computer also
revealed that days before the murders, Entwistle looked at a website that
described "how to kill people" ....
More at http://en.wikipedia.org/wiki/Neil_Entwistle
Casey Anthony
On the last day that two-year-old Caylee Anthony was seen alive (in 2008),
someone in Casey Anthony's house googled for "fool-proof suffication" [sic],
using Firefox. This was the browser primarily used by Casey; most other
household members used Internet Explorer.
Casey was acquitted in the case of Caylee's death. The prosecutor was not
aware of the Firefox search history, due to a police error.
How do such cases relate to the AOL search-data leak, and Thelma Arnold?
While none of the AOL individuals was charged with anything, some of their
searches (particularly those related to violent pornography) are rather
disturbing.
Where is google-search-history stored on your computer? Is
it stored anywhere, anymore? Does this make you more interested in duckduckgo.com
(and donttrack.us)?
Webcam Spying
If you have a laptop with a webcam, someone might turn it on. If your laptop
has a microphone, that can be turned on too.
Tyler Clementi
On September 19, 2010, Rutgers University Tyler Clementi asked his roommate
Dharun Ravi to be out of the room for the evening. Clementi then invited a
male friend and they kissed. Ravi, meanwhile, turned on his webcam remotely
from a friend's room, watched the encounter, and streamed it live over the
internet.
Ravi told friends he would stream the video again on September 21, but
Clementi turned off Ravi's computer. That night Clementi filed an official
invasion-of-privacy complaint with Rutgers, and requested a single room. The
next day Clementi leapt to his death from the George Washington bridge. His
exact motives remain unclear; his family did know he was gay.
How much is this about invasion of privacy?
How much is this about harassment of homosexuals?
How much is this about bullying?
What about Erin Andrews, the ESPN reporter who was videoed while undressed
in her New York hotel room, allegedly by Michael Barrett, apparently now
convicted? This video too was circulated on the internet; the case made
headlines in July 2009 (though when the videos were actually taken is
unclear). Barrett got Andrews' room number from the hotel, reserved a room
next to hers, and either modified the door peephole somehow, or drilled a
hole through the wall and added a new peephole.
Is Andrews' situation any different from Clementi's? (Aside from the part
about damages to hotel property).
What should the law say here? Is
it wrong to place security cameras on your business property? Is it wrong to
place "nannycams" inside your house? What sort of notice do you have to give
people?
When we record the ACM lectures at Loyola, what sort of notice do we have to
give the audience? The speakers?
Note that in Illinois it was a felony to record conversations
without the consent of all parties, even in a public place. Here is a note
about the New Jersey law.
Note:
Under New Jersey's invasion-of-privacy statutes, it is a fourth degree
crime to collect or view images depicting nudity or sexual contact
involving another individual without that person's consent, and it is a
third degree crime to transmit or distribute such images. The penalty for
conviction of a third degree offense can include a prison term of up to
five years.
New Jersey lists "nudity" and "sexual contact" as entitled to privacy; some
other states list "expectation of
privacy".
If Clementi killed himself simply because he had been "outed", then any sex
partner could have outed him legally.
Sex partners could not legally have filmed him without his consent, but
(like most celebrity sex tapes) a lover could later release a tape that had been made with consent, or simply
release a textual narrative.
Ravi was convicted on March 16, 2012 for the invasion of privacy and for
"bias intimidation"; the latter is commonly known as the "hate crimes"
statute. He was then sentenced to 30 days in jail, plus fines and probation.
Ravi was not charged with provoking the suicide itself.
Pennsylvania school laptops
In the Lower Merion school district in Ardmore PA, school-owned laptops were
sent home with students. School officials were accused in 2010 of spying on
students by turning on the laptops' cameras remotely, while the laptops were
in the students' homes.
The school's position is that remote camera activation was only done when
the laptop was reported lost or stolen, as part of the LANRev software
package (see also the open-source preyproject.com
site). Note that the current owners of LANRev now state:
We discourage any customer from taking
theft recovery into their own hands," said Stephen Midgley, the
company's head of marketing, in an interview Monday. "That's best left
in the hands of professionals."
Some sources:
Parents became aware of the incident when Blake Edwards, then 15, was called
into the principal's office:
The Robbinses said they learned of the
alleged webcam images when Lindy Matsko, an assistant principal at
Harriton High School, told their son that school officials thought he had
engaged in improper behavior at home. The behavior was not specified in
the suit.
"(Matsko) cited as evidence a photograph from the webcam embedded in minor
plaintiff's personal laptop issued by the school district," the suit
states. [AP article]
Ms Matsko had seen the student ingesting something that looked to her like
drug capsules; the student in question claimed it was Mike-and-Ike
candy and there was considerable corroborating evidence that that was the
case. It is not clear whether Matsko had formally disciplined the student.
Supposedly the laptop camera was activated because the laptop was reported
as missing, but that in the case in question Robbins had, according to the
school district, been issued a "loaner" laptop because he had not paid the
insurance fees for a regular laptop. Loaner laptops were not supposed to go
home with students, but it is not clear that Robbins was ever told that.
Furthermore, there were about two weeks' worth of photos collected by the
webcam, despite Robbins' regular attendance at school.
Some technical details, including statements made by Mike Perbix of the
school's IS department, are available at http://strydehax.blogspot.com/2010/02/spy-at-harrington-high.html.
The stryde.hax article made the following claims:
- Possession of a monitored Macbook was required for classes
- Possession of an unmonitored personal computer was forbidden and would
be confiscated
- Disabling the camera was impossible
- Jailbreaking a school laptop in order to secure it or monitor it
against intrusion was an offense which merited expulsion
The first, if true, would seem odd, in that generally students also have the
option of using school computing labs plus home computing resources; the
other points are fairly standard (though black electrical tape is
wonderfully effective at disabling what the camera can see).
The Strydehax article also makes it clear that Perbix had gone to some
lengths to disable the camera for student use, but to still allow the camera
to be used by the administrative account. Perbix had written on https://groups.google.com/group/macenterprise/browse_thread/thread/98dd9da15da4189f/d461836b9996c4d8?lnk=gst&q=perbix+isight
(google login may be necessary):
[to disable the iSight camera] You have can
simply change permission on 2 files...what this does is prevent internal
use of the iSight, but
some utilities might still work (for instance an external application
using it for Theft tracking etc)...I actually created a little Applescript
utility and terminal script which will allow you to do it remotely, or
allow a local admin to toggle it on and off.
Some students noticed that the LED by the camera occasionally blinked or
came on. They were apparently told this was a glitch, and not that the
camera was tracking them (student testimonials in this regard are on the
Strydehax site).
Before the laptops were even handed out, Perbix had replied to another
employee's concern with the following (from wikipedia):
[T]his feature is only used to track
equipment ... reported as stolen or missing. The only information that
this feature captures is IP and DNS info from the network it is connected
to, and occasional screen/camera shots of the computer being operated....
The tracking feature does NOT do things like record web browsing,
chatting, email, or any other type of "spyware" features that you might be
thinking of.
Note that public schools are part of the government, and, as such, must
abide by the Fourth Amendment (though schools may be able to search lockers
on school property). (Loyola, as a
private institution, is not so bound, though there are also several Federal
statutes that appear to apply.)
Students and parents do sign an Acceptable Use policy. However, a signature
is required for the student to be issued a laptop. Also, students are
minors, and it appears to be the case that parents are not authorized to
sign away the rights of minors.
A second student, Jalil Hasan, also had his webcam activated. He had
apparently lost his laptop at school; it was found and he retrieved it a
couple days later. However, his webcam was now taking pictures, and
continued to do so for two months.
In April 2010 the school's attorneys issued a self-serving report claiming
there was no "wrongdoing", but nonetheless documenting rather appalling
privacy practices. Some information from the report is at http://www.physorg.com/news192193693.html.
The most common problem was that eavesdropping was not terminated even after
the equipment was found.
In October 2010, the Lower Merion School District settled the Robbins and
Hasan cases for $610,000. Of that amount, 70% was for attorneys' fees.
The FBI did investigate for violations of criminal wiretapping laws.
Prosecutors eventually decided not to bring any charges. While there may not
have been criminal intent, the policies of the school and its IT group
showed a gross disregard for basic privacy rights. While "accidentally"
taking pictures remotely might be a possibility, going ahead and then using
those pictures (eg to discipline students, or even to share them with
teachers and academic administrators) is a pretty clear abuse of privacy
rules.
Another school-laptop case
Susan Clements-Jeffrey, 52-year-old long-term substitute teacher at Keifer
Alternative School (K-12) in Springfield OH, bought a used laptop from
one of her students in 2008. She paid $60 for it. That's cheap for a laptop,
but the non-free application software had been removed and, well, the case
sort of hinges on whether it was preposterously
cheap. The lowest prices I could find a couple years later for used laptops
were ~$75, on eBay.
The laptop in fact had been stolen from Clark County School District in
Ohio, and on it was LoJack-for-Laptops software to allow tracking. Once it
was reported missing, the tracking company, Absolute
Software, began tracking it. Normal practice would have been to track
it by IP address (the software "phones home" whenever the computer is
online, and then turn that information over to the police so they could find
out where it was located, but Absolute investigator Kyle Magnus went
further: he also recorded much communication via the laptop (including audio
and video).
Clements-Jeffrey used the laptop for "intimate" conversation with her
boyfriend. Absolute recorded all this, including at least one nude image of
Clements-Jeffrey from the webcam. Police eventually did come and retrieve
the laptop; theft charges were quickly dropped.
Clements-Jeffrey, however, has now sued Absolute for violation of privacy,
under the Electronic Communications Privacy Act that forbids interception of
electronic communication. Absolute's defense has been that Clements-Jeffrey
knew or should have known the laptop was stolen, and if she had in fact
known this then her suit would likely fail. However, it seems likely at this
point that she did not know this.
Absolute has also claimed that they were only acting as agent of the
government (ie the school district). The school district denies any
awareness that eavesdropping might have been done. And claiming that actions
on behalf of a school district are automatically "under color of law" seems
farfetched to me.
In August 2011, US District Judge Walter Rice ruled that Clements-Jeffrey's
lawsuit against Absolute could go forwards. In September there was an
undisclosed financial settlement.
More at http://www.wired.com/threatlevel/2011/08/absolute-sued-for-spying.
More on laptops and spying
This is continuing, though schools are not involved in the exploits
documented here:
http://www.wired.com/threatlevel/2012/09/laptop-rental-spyware-scandal/
Event data recorders in automobiles
Who owns the data? Should you know it is there?
What if it's explained on page 286 of the owners manual? Or on page 286 of
the sales contract, incorporated by reference (meaning they don't print that
out)
Should it be possible for the state to use the information collected against
you at a trial? What about the vehicle manufacturer, in a lawsuit you have
brought alleging manufacturing defects?
See Wikipedia: "Event_data_recorder"
Of perhaps greater concern, data recording in automobiles has since 2010
switched more and more to online connectivity. There is often no opt-out
feature. Most new cars now transmit data to the manufacturer in
real time. This includes information about the following:
- Vehicle engine performance
- Driving: how hard is the braking, turning and acceleration
- Phone calls placed through the vehicle
- Music preferences
- Location (via in-car GPS)
Connecting your phone via bluetooth introduces new privacy risks.
Generally you are asked if it is ok to upload your contact list; if you
agree, your car has that list in perpetuity. Also, probably, the car's
manufacturer. And possibly a log of all SMS messages you've ever sent or
received. Data can also be harvested if you plug your phone into the
vehicle USB port, simply to charge it.
Typical user "agreements" allow the manufacturer to sell any data they
collect to anyone. The US Customs and Border Protection agency doesn't buy
this data from manufacturers, however; they've purchased equipment to read
it directly from cars: theintercept.com/2021/05/03/car-surveillance-berla-msab-cbp.
For an overview, see washingtonpost.com/technology/2019/12/17/what-does-your-car-know-about-you-we-hacked-chevy-find-out.
Facebook and privacy
Is Facebook the enemy of privacy? Or is Facebook just a tool that has
allowed us to become the enemies of our own privacy?
Originally, access was limited to other users in your "network", eg
your school. That was a selling point: stuff you posted could not leak to
the outside world. Then that changed. Did anyone care?
Facebook privacy issues are getting hard
to keep up with! For example, what are the privacy implications of Timeline?
Switching to Timeline doesn't change any permissions, but all of a sudden
it's much easier for someone to go way back in your profile.
Facebook knows a lot about you. It
knows
- who your friends are
- what you are writing to whom (using facebook)
- your age
- your education
- your job (probably)
- your hobbies
- what you "like"
- whether you are outgoing (extraverted?) or not
Here's a timeline of the progressive privacy erosion at facebook: eff.org/deeplinks/2010/04/facebook-timeline
At one time (2009?) Facebook was actively proposing "sharing" agreements
with other sites, and made data-sharing with those sites the default. The
idea was that FB and the other site would share information about what you
were doing. Some of the sites (from
readwriteweb.com) are:
- yelp.com: a restaurant/shopping/etc
rating site (so you could post about restaurants to both yelp and FB?)
- docs.com: a googledocs competitor owned
by Microsoft (presumably the idea was you could post "docs" on your FB
page)
- pandora.com (the web-radio site)
Eventually Facebook has again stepped back from a full roll-out of the
sharing feature, although the shared-login feature seems to be coming back.
Facebook has long tinkered with plans for allowing a wide range of
third-party sites to have access to your facebook identity. Back in 2007,
this project was code-named Beacon.
Supposedly the Beacon project has been dropped, but it seems the idea behind
it has not.
Ironically, third-party sites might not need
Facebook's cooperation to get at least some information about their
visitors (such as whether they are even members of Facebook). Your browser
itself may be giving this away. See
http://www.azarask.in/blog/post/socialhistoryjs.
(Note that this technique, involving the third party's setting up
invisible links to facebook.com, myspace.com, etc, and then checking the
"link color" (doable even though the link is invisible!) to see if the
link has been visited recently, cannot reveal your username.)
In May 2010 Facebook made perhaps
their most dramatic change in privacy policy, when they introduced changes requiring that some of your information
be visible to everyone: your name, your schools, your interests, your
picture, your friends list, and the pages you are a "fan" of. Allegedly your
"like" clicks also became world-readable. (Here's an article by Vadim
Lavrusik spelling out why this can be a problem: http://mashable.com/2010/01/12/facebook-privacy-detrimental.
Lavrusik's specific concern is that he sometimes joins Facebook groups as
part of journalistic investigation, not out of any sense of shared interest.
But journalists always have these sorts of issues.)
After resisting the May 2010 uproar for a couple weeks, Facebook once again
changed. However, they did not
apologize, or admit that they had broken their own past rules.
Here's an essay from the EFF, http://www.eff.org/deeplinks/2010/05/facebook-should-follow,
entitled Facebook Should Follow Its Own
Principles, in which they point out that Facebook's 2009 principles
(announced after a similar uproar) state
People should have the freedom to decide
with whom they will share their information, and to set privacy controls
to protect those choices.
But Facebook's initial stance in 2010 was that users always had the freedom
to quit facebook if they didn't like it. Here's part of Elliot
Schrage, FB VP for Public Policy, as quoted in a May 11, 2010 article at http://bits.blogs.nytimes.com/2010/05/11/facebook-executive-answers-reader-questions:
Joining
Facebook is a conscious choice by vast numbers of people who have
stepped forward deliberately and intentionally to connect and share. We
study user activity. We've found that a few fields of information need to
be shared to facilitate the kind of experience people come to Facebook to
have. That's why we require the following fields to be public: name,
profile photo (if people choose to have one), gender, connections (again,
if people choose to make them), and user ID number.
Later, when asked why "opt-in" (ie initially private) was not the default,
Schrage said
Everything is opt-in on Facebook.
Participating in the service is a choice. We want people to continue to
choose Facebook every day. Adding information -- uploading photos or
posting status updates or "like" a Page -- are also all opt-in. Please
don't share if you're not comfortable.
That said, much of your core information is still public by default.
Facebook has moved to a default setting for posts of "share only
with friends".
Two weeks after Schrage's claim that users would always be free not to use
Facebook if they didn't like it, Facebook CEO Mark Zuckerberg weighed in,
with a May 24, 2010 article in the
Washington Post: http://www.msnbc.msn.com/id/37314726/ns/technology_and_science-washington_post/?ns=technology_and_science-washington_post.
In the article, Zuckerberg does not seem to acknowledge that any mistakes
were made. He did, however, spell out some Facebook "principles":
- You have control over how your information is
shared.
- We do not share your personal information with
people or services you don't want.
- We do not give advertisers access to your
personal information.
- We do not and never will sell any of your
information to anyone.
- We will always keep Facebook a free service for
everyone.
The first principle is a step back from the corresponding 2009 principle.
Facebook vigorously claims that your information is not shared with
advertisers, by which they mean that your name is not shared. However, your
age, interests, and general location (eg town) are
shared, leading to rather creepy advertisements at best, and cases where
your identity can be inferred at worst.
Recall that advertisers are Facebook's real customers. They are the ones who
pay the bills. The users are just users.
Deja News, once at deja.com (now run by google): where is it now? It still
lets you search archives of old usenet posts, though the social significance
of that is reduced in direct proportion to the reduced interest in Usenet.
Think of being able to search for someone's years-old facebook posts, though
(and note that Facebook Timeline has in effect enabled just this).
Facebook
news-feeds
Baase 4e p 76 / 5e p 69
Originally, you only saw what your friends did when you reloaded their page.
News feeds (mini-feeds) implemented active
notification to your friends whenever you change your page. Why was this
considered to be a privacy issue? Is it still considered to be a privacy
issue?
The mini-feed issue originally came up in 2006. However, modifications of
the feature still occasionally reopen the privacy issue. At this point,
though, most people have come to accept that nobody understands when their
posts appear in someone else's post feed.
Is this a privacy issue or not?
Here's a view at the time, from theregister.co.uk/2006/09/07/facebook_update_controversy:
Users protest over 'creepy' Facebook update
The introduction of new features on social
network site Facebook has sparked a backlash from users. Design changes to
the site violate user privacy and ought to be scrapped, according to
disgruntled users who have launched a series of impromptu protests. One
protest site is calling for users to boycott Facebook on 13 September in
opposition against a feature called News Feed, which critics argue is a
Godsend for stalkers.
Would you say, today, that your Facebook newsfeed is "creepy"?
Whatever one says about Facebook and the loss of privacy, it is pretty
clear to everyone that posting material to Facebook is
under our control, though perhaps only in the sense that we
participate in Facebook voluntarily. Thus, the Facebook privacy question
is really all about whether we can control
who knows what about us, and continue
to use Facebook.
(Facebook does track all visitors, Facebook users or not, on
any web page with an embedded Facebook "like" button, but that's a
separate issue.)
Cambridge Analytica
Suppose Alice tells Bob a secret. Bob then goes to a party at Zuck's and
tells Charlie. How angry at Charlie should Alice get? At Zuck?
Aleksandr Kogan developed a Facebook quiz app, "This Is Your Digital
Life", in 2013. By 2015, some 300,000 Facebook users took it. The terms of
service granted access to the user's Facebook data, at least to the basic
data. That included the information about your friends that they had made
available to you.
The quiz was actually administered by Cambridge Analytica. Due to the
friends amplification, they obtained information on somewhere between 30
and 87 million Facebook users.
Cambridge Analytica used the data collected to try to identify the
political leanings of each person for whom they obtained data, and also to
identify the political issues the person would be most interested in.
The Obama campaign had tried something similar, but users were fully
aware that they were granting information to a political organization. The
This Is Your Digital Life quiz had no indication that it was anything
other than any of those many "harmless" quizzes on Facebook.
The 2016 Trump campaign hired Cambridge Analytica; the data was used in
that campaign.
Should Facebook ever have let outside "apps" access data on
Friends? They stopped this in 2014, but Kogan's app was grandfathered in.
Data from the app was supposed to be deleted, but Facebook didn't make an
effort to confirm this. In 2018, Facebook cracked down much harder on apps
being allowed access to any Friend data at all (though it's not clear it's
blocked completely).
It is unlikely the data was of much use in the 2016 campaign. Both
political parties provide the same information, in much more usable and
accurate form. And it has limited utility in getting people to vote, and
very limited utility in getting people to change their vote.
Facebook and unrelated sites
Facebook now shows up on unrelated sites. Sites are encouraged to enable the
Facebook "like" button, and here's an example of theonion.com displaying my
(edited) friends and their likes: http://pld.cs.luc.edu/ethics/theonionplusFB.html.
How much of this is an invasion of privacy?
While Facebook does seem interested in data-sharing agreements with non-FB
sites, it is often not at all clear when such sharing is going on. The two
examples here, for example, do not necessarily involve any sharing. An
embedded "like" button, when clicked, sends your information to Facebook,
which can retrieve your credentials by using cookies. However, those
credentials are hopefully not
shared with the original site; the original site may not even know you
clicked "like". As for the box at theonion.com listing what my friends like,
this is again an example of "leased page space": Facebook leases a box on
theonion.com and, when you visit the site, it retrieves your FB credentials
via cookie and then fills in the box with your friends' "likes" of Onion
articles. The box is like a mini FB page; neither the likes nor your
credentials are shared with The Onion.
One concern with such pseudo-sharing sites is that they make it look like
sharing is in fact taking place, defusing objections to such sharing. If
someone does object, the fact that no sharing was in fact invoved can be
trotted out; if there are not many objections, Facebook can pursue "real"
sharing agreements with confidence. They also make it harder to tell when
objectionable sharing is occurring.
An example of a true data-sharing agreement would be if a restaurant-review
site let you log into their site
using your Facebook cookies, and
then allowed you to post updates about various restaurants.
Facebook "connections": http://www.eff.org/deeplinks/2010/05/things-you-need-know-about-facebook
Your connections are not communications with other users, but are links to
your school, employer, and interests. It is these that Facebook decided to
make "public" in May 2010; these they did back off from.
Facebook and Advertising
Facebook claims that user data is not turned over to advertisers, and
this seems true (with a couple slip-ups): advertisers supply criteria
specifying to whom their ads will be shown, and Facebook shows the ads to
those users. For example, a few years ago I would regularly see ads for
"Illinois drivers age 54", but this didn't mean that Facebook had turned
over my age. What happened is that the advertiser has created an ad for
each age 30-65, and asked Facebook to display to a user the one that
matches his or her age. This is misleading, but information is not shared
directly.
Since then, Facebook has disallowed this type of ad:
Ads must not contain content that
asserts or implies personal attributes. This includes direct or
indirect assertions or implications about a person’s race, ethnic
origin, religion, beliefs, age, sexual orientation
or practices, gender identity, disability, medical condition
(including physical or mental health), financial status, membership
in a trade union, criminal record, or name.
Once you click on an ad, however, the advertiser does know what ad you are
responding to, and thus would know your age in the example above.
There was a slip-up a couple years ago where game sites (often thinly veiled
advertising) were able to obtain the Facebook ID of each user. Here's what
they say:
In order to advertise on Facebook,
advertisers give us an ad they want us to display and tell us the kinds of
people they want to reach. We deliver the ad to people who fit those
criteria without revealing any personal information to the advertiser.
For more information on how to do this, see http://www.facebook.com/adsmarketing/index.php?sk=targeting_filters.
Facebook supports targeting based on:
- Location, as determined from your IP address
- Language (eg Spanish-speaking residents of the Chicago area)
- Age and sex
- Likes and Interests. I decided to "like" horseback riding several
years ago. It took a couple years for any related ads to show up, but
now they do so regularly.
- Connections: did someone Like your page? Did someone rsvp to your
event? Play your game? You can also target their Friends.
- Advanced Demographics: birthdays, schools and professions
Note that you don't get to choose what attributes advertisers can use,
because advertisers do not see them! And Facebook itself has access to
everything (duh).
For a while it was possible to specify the ad-selection terms very
precisely (including the use of the user's "network"), even to the point
of displaying an ad to a single user (though this was not supposed to
work). Here's a blog post from late 2017 on doing exactly this: medium.com/@MichaelH_3009/sniper-targeting-on-facebook-how-to-target-one-specific-person-with-super-targeted-ads-515ba6e068f6.
But this has now been fixed; see thetyee.ca/News/2019/03/06/Facebook-Flaw-Zero-In/.
Supposedly, post-Cambridge-Analytica, Facebook has cracked down on this
sort of thing. But it's hard to be sure what they did.
Targeting by email
Go to settings → ads (on left) → Advertisers and Businesses → Who
uploaded a list with your info and advertised to it.
What this means is that advertisers can target you on Facebook even if no
interests match. The uploaded lists can be based on email addresses, phone
numbers, Facebook UIDs, Apple or Android advertising IDs [!], or other.
See developers.facebook.com/docs/marketing-api/reference/custom-audience.
It is not very clear what Facebook does to prevent advertisers from
uploading huge email lists for Facebook to spam.
Also, Facebook does run a full-scale advertising network. Non-Facebook
websites include ads from this network, just as they include Google ads.
Facebook identifies that it's you by your Facebook browser cookie, and
serves up the ads.
Suggestions: don't give Facebook your regular email address. I know,
kinda late now.
For what it's worth, here are Facebook's basic advertising policies: facebook.com/policies/ads.
This targeting-by-email advertising category may account for a large
chunk of Facebook's advertising revenue, though Facebook doesn't publish
statistics.
Engagement
Facebook is able to provide evidence of engagement, typically with
organization pages, in ways that advertisers outside of Facebook and
Google cannot do (and maybe not even Google). See
In fact, it is possible to declare engagement to be the
objective of your ad campaign. You then get billed based, not on clicks,
but on the basis of a "page post engagement metric", including clicks,
likes, shares, comments and video views. (Some of these are considered active;
others passive.) For advertisers, this approach is often a good
deal. Advertisers end up paying for engagement rather than clickthroughs.
Facebook supports a complex system of advertising objectives. See facebook.com/business/ads-guide/image/facebook-feed/post-engagement.
Facebook is perhaps the only online advertiser that can measure
interaction (maybe Google can, through YouTube), because they both run the
site and serve up the ads.
Like → advertisement
FB "likes" have long been somewhat randomly displayed to Friends. But in
2012 FB added a new feature: social
advertisements, or Sponsored Stories.
If you "like" something on Facebook, it may automatically be converted to an
advertisement, paid for by the company whose product you liked.
Here's an example: http://www.nytimes.com/2012/06/01/technology/so-much-for-sharing-his-like.html?_r=2.
Nick Bergus discovered that Amazon was selling personal lubricant in
55-gallon-drum quantities, and posted a satirical "like". Actually, he
posted a comment. Much to Nick's surprise, his "comment" became part of an
ad for the product shown to his friends, paid for by Amazon; FB's policy is
that an advertiser may purchase any likes/comment it wishes and convert them
to paid ads, with no royalties to the liker. Such "social ads" are displayed
only to friends of the liker [if I understood this correctly]. Note,
however, that presumably none of Mr Bergus' friends would have been targeted
for this particular ad if Mr Bergus hadn't "endorsed" the product. Alas for
FB, Amazon and perhaps Mr Bergus, FB's ad-selection mechanism seems to be
clueless about the realities of sarcasm.
Here is the relevant part of the policy, from May 2012, still in place
October 2013:
10.
About Advertisements and Other Commercial Content Served or Enhanced
by Facebook
Our goal is to deliver ads that are not
only valuable to advertisers, but also valuable to you. In order to do
that, you agree to the following:
- You can use your privacy
settings to limit how your name and profile picture may be
associated with commercial, sponsored, or related content (such as a
brand you like) served or enhanced by us. You give us
permission to use your name and profile picture in connection with
that content, subject to the limits you place.
- We do not give your content or information to advertisers without
your consent.
- You understand that we may not always identify paid services and
communications as such.
In June 2012, Facebook agreed to make it clearer to users when this is
happening. The above policy is presumably the "clearer" policy.
Conversely, if you do not use your
privacy settings to limit how your identity may be used in ads, you have
agreed to such use!
Here are FB's
rules for social ads:
-
Social ads show an advertiser's message alongside
actions you have taken, such as liking a Page
-
Your privacy settings apply to social ads
-
We don't sell your information to advertisers
-
Only confirmed friends can see your actions alongside
an ad
-
If a photo is used, it is your profile photo and not
from your photo albums
I tried setting my social-ad preferences. I found them at Privacy
Settings → Ads, Apps and Websites → Ads → Edit Settings. My settings were
"no one"; I have no idea why.
Facebook and Political Ads
After Cambridge Analytica, Facebook increased its monitoring of political
ads. Much of the spending data is now public. To view it, start at the
Facebook Ad Library page, facebook.com/ads/library/?active_status=all&ad_type=political_and_issue_ads&country=US.
Search for "The People For Bernie Sanders". You have to get the
organization exactly right. Try typing the candidate name, and then using
the down-arrow.
It can be very hard to get the correct search term that identifies the
political organization, and thus the ad spending. You are looking for a
pair of boxes, the leftmost one titled "Total spent by Page on ads related
to politics or issues of importance". Alternatively, try these:
Facebook data
Some have argued that Facebook privacy issues have shifted: the data you
post is no longer the real issue at all (after all, more and more users are
comfortable with the control they have over that data). The real issue is
the data that Facebook collects from you in their role as an advertiser.
They know what you like, what you "like", and what you actually click on. In
some ways, this is similar to Google. In other ways, Facebook has those
pictures, and arguably even more metadata to play with.
See saintsal.com/facebook/
Facebook and privacy more fine-grained than the Friend level
What if you've Friended your family, and your school friends, and want to
put something on your wall that is visible to only one set? The original
Facebook privacy model made all friends equal, which was sometimes a bad
idea. Facebook has now introduced the idea of groups:
see http://www.facebook.com/groups.
Groups have been around quite a while, but have been repositioned by some
(with Facebook encouragement) as subsets of Friend pools:
Have things you only want to share with a
small group of people? Just create a group, add friends, and start
sharing. Once you have your group, you can post updates, poll the group,
chat with everyone at once, and more.
For better or worse, groups are still tricky to manage, partly because they
were not initially designed as Friend subsets. When posting to a group, you
have to go to the group wall; you can't put a message on your own wall and
mark it for a particular group. News feeds for group posts are sometimes
problematic, and Facebook does not make clear what happens if a group
posting is newsfed to your profile and then you Comment on it. You may or
may not have to update your privacy settings to allow group posts to go into
your newsfeed. Privacy Settings do not mention Groups at all (as of June
2011).
Maybe the biggest concern, however, is that Facebook's fast-and-furious
update tradition is at odds with the fundamental need to be meticulous when
security is important.
That said, some people are quite successful at using FB's privacy features
here.
Google+ came out with circles,
which promptly changed all this. FB has now introduced new competitive
features (groups), which I have been too lazy to bother with. (Part of the
issue is that FB groups were invented to deal with larger-scale issues; as
originally released they were an awkward fit for subsets of Friends.)
But the issue is not really whether they work.
Here's a technical analogue: are NTFS file permissions better than
Unix/Linux? Yes, in the sense that you can spell out who has access to what.
But NTFS permissions are very difficult to audit and to keep track of; thus,
in a practical sense, they have
been a big disappointment.
Facebook and Facial
Recognition
Does this matter?
Here's an article from August 2012: http://news.cnet.com/8301-1023_3-57502284-93/why-you-should-be-worried-about-facial-recognition-technology/,
and related articles linked to that.
Even today, Facebook appears to be using this technology to suggest how to
tag people in photos. Is this a concern? If the technology catches on, might
other uses make it become a concern? Could Facebook also be using this
technology to identify those who create Facebook accounts not using their
real name?
Here's a 2015 article: FaceBook
will soon be able to ID you in any photo
The article here is from the publishers of Science.
FaceBook is way ahead of the FBI in this regard.
Facebook has claimed that this new feature will protect your
privacy: "you will get an alert from Facebook telling you that you appear in
the picture,.... You can then choose to blur out your face from the picture
to protect your privacy." Is that likely? After all, if you're tagged
in the picture then they don't need facial recognition, and if you're not
tagged, is this a serious issue?
FaceBook's DeepFace system was trained on all those FB pictures in which
people are tagged. Did you know you agreed to that?
Police could use such a system to identify people on the street, or
participants at a rally. Stalkers could use it to find out the real identity
of their chosen victim.
Facebook does not make their entire face library public, though they do
make profile pictures public. Vkontakte, in
Russia, apparently makes more images public, and a facial-identification
app FaceFind has been created using Vkontakte's image library. Given a
picture of a person (even in a crowd), it supposedly can identify the
person around 70% of the time. See https://www.theguardian.com/technology/2016/may/17/findface-face-recognition-app-end-public-anonymity-vkontakte.
Clearview is now available in the US; it is a
similar facial-identification tool. Officially, Clearview is only
available to the police, and maybe also to those who consider themselves
to be "investigators".
Finally, here is a lengthy essay by Eben Moglen, author of the GPL, on
"Freedom in the Cloud: Software Freedom, Privacy, and Security for Web 2.0
and Cloud Computing": http://www.softwarefreedom.org/events/2010/isoc-ny/FreedomInTheCloud-transcript.html.
Mr Moglen adds some additional things that can be inferred from
Facebook-type data:
- Do I have a date this Saturday?
- Who do I have a crush on (whose page am I obsessively reloading)?
You get free email, free websites, and free spying too!
Mr. Zuckerberg has attained an unenviable
record: he has done more harm to the human race than anybody else his age.
Because he harnessed Friday night. That is,
everybody needs to get laid and he turned it into a structure for
degenerating the integrity of human personality and he has to a remarkable
extent succeeded with a very poor deal. Namely, 'I will give you free web
hosting and some PHP doodads and you get spying for free all the time'.
And it works.
Later:
I'm not suggesting it should be illegal. It
should be obsolete. We?re technologists, we should fix it.
Did Google+ fix anything? Does anyone trust google more than Facebook?
Google+ circles do seem easier to use.
Facebook 2010 settings
Here are some of the June 2010 Facebook privacy settings (that is, a month
after the May 2010 shift), taken from privacy settings ? view settings
(basic directory information). Note that there is by this point a clear
Facebook-provided explanation for why some things are best left visible to
"everyone".
At the time I collected these, the issue was that FB provided explanations,
and defaults. In retrospect, the issue is what happened to all these
settings?
Your name, profile picture, gender and
networks are always open to everyone. We suggest leaving the other basic
settings below open to everyone to make it easier for real world friends
to find and connect with you.
* Search for me on Facebook
This lets friends find you on Facebook. If you're visible to fewer people,
it may prevent you from connecting with your real-world friends.
Everyone
* Send me friend requests
This lets real-world friends send you friend requests. If not set to
everyone, it could prevent you from connecting with your friends.
Everyone
* Send me messages
This lets friends you haven't connected with yet send you a message before
adding you as a friend.
Everyone
* See my friend list
This helps real-world friends identify you by friends you have in common.
Your friend list is always available to applications and your connections
to friends may be visible elsewhere.
Everyone
* See my education and work
This helps classmates and coworkers find you.
Everyone
* See my current city and hometown
This helps friends you grew up with and friends near you confirm it's
really you.
Everyone
* See my interests and other Pages
This lets you connect with people with common interests based on things
you like on and off Facebook.
Everyone
Here are some more settings, from privacy settings => customize settings
(sharing on facebook)
* Things I share
| Posts by me (Default setting for posts, including status updates
and photos) |
Friends Only |
| Family |
Friends of Friends |
| Relationships |
Friends Only |
| Interested in and looking for |
Friends Only |
| Bio and favorite quotations |
Friends of Friends |
| Website |
Everyone |
| Religious and political views |
Friends Only |
| Birthday |
Friends of Friends |
.
* Things others share
| Photos and videos I'm tagged in |
Friends of Friends |
| Can comment on posts |
Friends Only |
| Friends can post on my Wall |
Enable |
| Can see Wall posts by friends |
Friends Only |
* Contact information
o Friends Only
The core problem here is not that these settings are hard to do, or that the
defaults are bad. The core problem is simply that you keep having to make new settings, as things evolve.
Examples:
- whether you can be tagged in other people's photos
- whether FB facial-recognition software is applied to other people's
photos of you
- whether you appear in other people's mini-feeds on you
- how far can friends search back in time on your wall
Another issue is whether the settings options are user-friendly. Here's a
technical analogue: are NTFS file permissions better than Unix/Linux? Yes,
in the sense that you can spell out who has access to what. But NTFS
permissions are very difficult to audit and to keep track of; thus, in a practical sense, they have been a huge
disappointment.
Facebook 2013 Settings
Facebook's current (2013) settings are, if anything, a step
towards greater inscrutability, though the new settings are
briefer. You are only given options to control who can see your posts
and who can look you up. (Photo albums have their own controls.)
Whether others can see your friend lists, or your personal information, is
no longer something you can control directly.
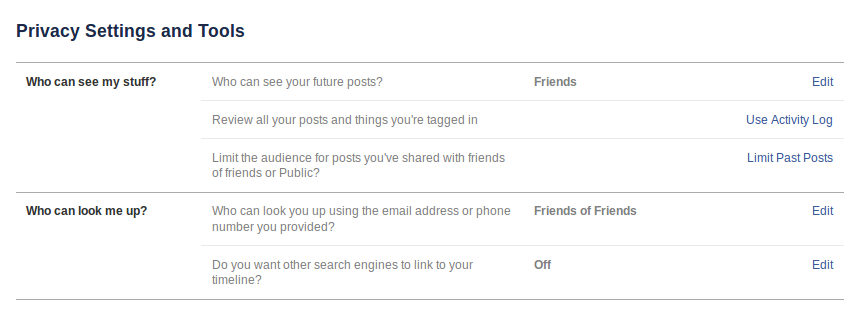
Later in 2013, a section "Who can contact me" was added, with options for
controlling who can send you Friend requests and who can send you messages.
The mechanism for limiting people from seeing past posts on your
timeline turns out never to be explained, and there are dire warnings
against even using it:
Limit The Audience for Old Posts on Your Timeline
If you use this tool, content on your timeline
you've shared with friends of friends or Public will change to
Friends. Remember: people who are tagged and their friends may see
those posts as well. You also have the option to individually change
the audience of your posts. Just go to the post you want to change
and choose a different audience.
Limit Old Posts
If you click the last thing, you get
You are about to limit old posts on your
timeline without reviewing them. Note: This global change can't
be undone in one click. If you change your mind later, you'll
need to change the audience for each of these posts one at a time.
You do now have a rather different way to review posts and photos by others
that you are tagged in.
You also have greater control over visibility of specific posts.
You can set the visibility of your friends list by going to friends =>
edit.
You can set the visibility many of 2010's "Things I share" by going to the
individual shared item and editing its sharing status. That is, sharing
policy is no longer all in one place; it is associated with each separate
item shared instead.
As far as I can tell, there is no longer a distinction between permission to
"post on your wall" and permission to "comment on a post".
And see http://www.facebook.com/help/204604196335128/,
for other lists of friends, including your "close friends" list. (Who can
see your "close friends" list?)
Facebook Elections
Facebook called for a policy-change election in December 2012. 79,731 voted
for the policy change; 589,141 voted against. Facebook officially declared,
however, that they required 30% participation (~300 million people!) to make
the vote binding.
Facebook decided to ignore the Will Of The Users.
They also, as part of the process, abandoned user voting.
Security researcher Suriya Prakash
discovered how to get your phone number from Facebook.
It turns out that Facebook allows by default a search for your page given
your phone number. You can turn this off, but (once again) only
if you know it is on. (It is in the privacy-settings category "How
you connect", which is rather misleading.)
So the idea is to search for all numbers, 000-000-0000 to 999-999-9999 and
get the name of each user. Then sort the table by name. All this is quite
practical; Prakash has said he has a table of about 5 x 108
numbers.
(Normally, if you're going to allow looking people up using an identifier
that isn't meant to be public, you implement a rate-limit on searches
per second, to disable Prakash's idea. Facebook failed to do this.)
If you know the area code, you can refine the search easily.
Get Your Loved Ones Off Facebook
That's the title of a famous
blog post by Salim Virani. Does he overstate the case? Or is Facebook
really dangerous?
Facebook does appear to follow your privacy preferences when you post
things. But that's not the whole story.
It is true that Facebook changes their Terms of Service and Privacy Rules
regularly. You don't get notifications of these changes. Is that bad?
Here are some things that Virani documents, though, that not everyone is
aware of:
- Facebook collects a lot of information about you outside of
what you upload or post. This information they are much freer to use
(and misuse). Generally, Facebook appears to keep "Like" clicks in this
category. Facebook has long created "social advertising" based on your
Likes (#facebook_advertising)
- If a non-Facebook page has an embedded Facebook "Like" button (or any
other FB applet), then Facebook can track that you've been to that page.
Lots of advertisers can track you this way, but only Facebook (and
Google, if you're logged in to your google account) can identify
you.
- Facebook is pushing to have most posted videos within the Facebook
system. This way Facebook can track exactly how much you watched, and
doesn't give up any advertising revenue to YouTube.
- Facebook's facial recognition system appears to be impossible to opt
out of. Even if you're not a Facebook user.
- The Facebook smartphone app tracks your location. It also enables
the microphone (at least, you have to grant it that permission to
install the app on Android). Lots of apps demand the ability to enable
the microphone. What are they all using it for? What is Facebook using
this for? The original theory was that they wanted to monitor what TV
shows you had on in the background.
- Facebook has a very accurate personality model for you.
- Facebook sometimes shows you little surveys
that look legitimate but are really intended to discover if any of your
friends are using fake names. But Facebook does not necessarily close
those accounts.
- If you're not on Facebook, they probably maintain an account for you
anyway, so they have a single identifier by which to index all those
photos of you that other people post. And any other information other
people post about you.
Some of the concerns expressed by Virani are unproven. But they all are
definitely plausible. Do you care?
Data Bureaus
If it's called a credit bureau, they keep track of your
credit-worthiness. In the US, credit reports are based on payment history,
almost entirely. There are three main credit bureaus: Equifax, Experian
and Trans-Union.
Use of this information for non-credit purposes, such as car
insurance, health insurance and employment, is often illegal, and in any
jurisdiction you have to be informed if you are denied a service based on
a negative credit report. So there is a great deal of interest in being
able to buy "credit-like" reports that are not called credit
reports. Hence the rise of data bureaus, which sell the
same data as credit bureaus, but, because they do not use the word
"credit" in their reports, they (and their customers) are not required to
comply with the rules that cover credit reporting.
SocialIntel
How about this site: Social Intelligence Corp, www.socialintel.com.
What they do is employee background screening. They claim to take some of
the risk out of do-it-yourself google searches, because they don't include
any information in their report that you are not supposed to ask for. What
they do is gather all the public Facebook information about you (and also
from other sources, such as LinkedIn), and store it. They look, in
particular, for
- racially insensitive remarks, such as that English should be the
primary language in the US
- membership in the Facebook group "I shouldn't have to press 1 for
English. We are in the United States. Learn the language."
- sexually insensitive remarks or jokes or links
- displays of weaponry, such as your Remington
.257 hunting rifle or your antique Japanese katana sword
While they do not offer this upfront, one suspects they also keep track of
an unusually large number (more than four?) of drunken party pictures.
Think you have no public Facebook information, because you share only with
Friends? Look again: the information does not have to have been posted by
you. If a friend posts a picture of you at a party, and makes the album
world-viewable, there may have gone your chance for that job at Microsoft.
To be fair, Social Intelligence is still fine-tuning their rules; the latest
version appears to be that they keep the information for seven years, but
don't release it in a report unless it's still online at the time the report
is requested. Unless things
change, and they need to go back to the old way to make more money.
In June 2011 the FTC ruled that Social Intelligence's procedure was in
compliance with the Fair Credit Reporting Act.
See:
Is this a privacy issue?
SocialIntel was one of the first companies to harvest Facebook data, selling
it mostly to prospective employers. There are now a large number of firms
that specialize in collecting Facebook public data, analyzing it, and
selling "threat reports" to police departments and private security-related
firms. See http://littlesis.org/news/2016/05/18/you-are-being-followed-the-business-of-social-media-surveillance/.
One company, ZeroFox, allegedly
tracked Black Lives Matter protesters. A similar company, Geofeedia,
also has police contracts. Both firms do a significant amount of commercial
"reputation management" work as well.
The big "mainstream" data bureaus are ChoicePoint
and Acxiom. (ChoicePoint is now LexisNexis.com/risk
(for Risk Solutions)) (Baase 5e p 63ff)
Look at the websites. Are these sites bad?
What if you are hiring someone to work with children? Do such employees have
any expectation of privacy with regard to their past?
ChoicePoint sells to government agencies data that those agencies are often
not allowed to collect directly. Is
this appropriate? (One law-enforcement option is their Accurint
database.)
ChoicePoint and Acxiom might argue that they are similar to a credit bureau,
though exempt from the rules of the Fair Credit Act because they don't
actually deal with credit information. Here is some of the data
collected (from Baase 3e):
- credit data
- divorce, bankruptcy, and other legal records
- criminal records
- employment history
- education
- liens
- deeds
- home purchases
- insurance claims
- driving records
- professional licenses.
(By the way, if a company offering you for a job pushes you hard to tell
them your birthdate, which is illegal for companies with four or more
employees, they are probably after it in order to search for
criminal-background data.)
Zhima Credit
Data collection could be worse. If you live in China, you probably pay
for things with Alipay (or WeChat Pay). Pretty much every transaction
leaves a record. The Alipay system allows icons (apps) within it. One of
them is Zhima (Sesame).
Zhima is a credit-score system. If you sign up, you get a credit score.
But it's not quite like the FICO score used in the US; there are lots of
additional factors. Some of these relate to a scoring system the Chinese
government was considering, called social credit. In
addition to whether you pay your bills on time (and pay government fines
on time), Zhima considers (or would like to consider) the following:
- What goods you buy
- Your education, and where you work
- Scores of your Friends (in Alipay)
- Whether you cheated on the college entrance exam
- Whether you failed to pay any fines
Your Zhima score is also public.
From Zhima: "Zhima Credit is dedicated to creating trust in a commercial
setting and independent of any government-initiated social credit system.
Zhima Credit does not share user scores or underlying data with any third
party including the government without the user's prior consent". Or,
perhaps, a government order.
Under the "social credit" system, people were supposed to have their
scores reduced if they were "spreading online rumors".
If your Zhima score is not excellent, you can still use many of the same
services, but you will have to provide a deposit. One car-rental agency
allows rentals without a deposit to those whose Zhima score is over 650
(new users start at 550). At one point, a score of over 750 let you bypass
the security scan at Beijing airport. High scorers also get preferential
placement on dating apps.
For a detailed article on Zhima, from a western perspective, see www.wired.com/story/age-of-social-credit.
It could be worse. Compare Zhima to the social surveillance faced by
the Uighur population of China's Xinjiang province:
nytimes.com/2018/02/03/opinion/sunday/china-surveillance-state-uighurs.html
Imagine that this is your daily life: While on
your way to work or on an errand, every 100 meters you pass a police
blockhouse. Video cameras on street corners and lamp posts recognize your
face and track your movements. At multiple checkpoints, police officers
scan your ID card, your irises and the contents of your phone. At the
supermarket or the bank, you are scanned again, your bags are X-rayed and
an officer runs a wand over your body....
A more detailed article is at www.engadget.com/2018/02/22/china-xinjiang-surveillance-tech-spread,
which also outlines the spread of the Chinese technology to other
authoritarian governments.
Social Credit Here
Could it happen here? The most likely is not a government-sponsored
system (though the TSA No-Fly list has some elements of this), but rather
a private system. Already Uber, Lyft and Airbnb ban certain users for
"inappropriate" behavior; these bans cannot be appealed. Insurance
companies are also collecting private "social credit" information about
potential customers. Some bar owners use PatronScan, a private blacklist
for bar patrons.
See fastcompany.com/90394048/uh-oh-silicon-valley-is-building-a-chinese-style-social-credit-system.
The International Monetary Fund published a blog post in 2020 suggesting
that incorporating your browsing history in your credit score would be a
good idea; see blogs.imf.org/2020/12/17/what-is-really-new-in-fintech.
The authors write:
Fintech resolves the dilemma [of traditional
credit scores of people with limited credit history] by tapping various
nonfinancial data: the type of browser and hardware
used to access the internet, the history of online searches and
purchases. Recent research documents that, once powered by
artificial intelligence and machine learning, these alternative data
sources are often superior than traditional credit assessment methods, and
can advance financial inclusion, by, for example, enabling more credit to
informal workers and households and firms in rural areas.
This would help some people who can't get a credit card because
they have no credit history, and can't get a credit history because they
have no credit card. But what searches would count as good? What would
count as bad? The blog authors claim AI will figure it out.
Arguably, the blog post was more of a "trial balloon" than a serious
proposal. One issue remaining is just how to associate names with browsing
history, with accuracy comparable to that typical of credit-history data.
But in general the banking industry is quite worried about "fintech"
moving to Amazon, Google and others.
But see www.extremetech.com/internet/326088-should-your-web-history-impact-your-credit-score-the-imf-thinks-so,
for a discussion of why machine learning is not going to be able to manage
this, and why the US would need a large expansion of regulation to be sure
banks were not abusing the feature.
The European Data Protection Supervisor (part of the EU) has advised
against using browsing data for credit scoring. They likewise advise
against the use of health information in credit scoring. The EDPS states
that the use of this kind of data "cannot be reconciled with the
principles of purpose limitation, fairness and transparency, as well as
relevance, adequacy or proportionality of data processing".
Facial Recognition
Facial recognition has been expanding much faster than the scope of our
regulations, or even social norms. Facial recognition has the potential to
end privacy when in public spaces.
Schools, sporting events, stores and restaurants are often concerned with
security in general. The AnyVision product is marketed to such places. It
can track the presence of unauthorized visitors to schools, of known
shoplifters to stores, and simply of repeat visitors. See themarkup.org/privacy/2021/07/06/this-manual-for-a-popular-facial-recognition-tool-shows-just-how-much-the-software-tracks-people
for examples of how such software is used.
The Chinese company TenCent now uses facial recognition to prevent minors
from playing certain games after hours, in order to comply with a national
game curfew. See www.nytimes.com/2021/07/08/business/video-game-facial-recognition-tencent.html.
Because teens sometimes use parents' phones, the technology is used for everyone.
Facial recognition used to have a strong racial bias: African-American
faces were much likely to result in false-positive matches; that is,
innocent people were identified as matches to the suspect. This was
apparently due to the fact that training data consisted almost entirely of
white and Asian faces. This bias has supposedly largely been fixed. That
said, note this article, which claims that, well, here's the August 2023
title:
In
every reported case where police mistakenly arrested someone using
facial recognition, that person has been Black
Some times, virtually no followup analysis was done after a
facial-recognition match before issuing a warrant. Porcha Woodruff was
arrested after a false match, despite being eight months pregnant, while
the suspect was clearly not pregnant at all: www.nytimes.com/2023/08/06/business/facial-recognition-false-arrest.html.
Clearview
Clearview is a program that attempts
to identify people from a photograph. In this it is much like Facebook's DeepFace (internal to Facebook)
or VKontakte-based FaceFind (available to the public, but covering only
Russia). [There is also Amazon's Rekognition.] The idea is that billions
of identified facial photos have been processed, so that, when the system
is presented with a new face photo, it can quickly find the best match.
Clearview is marketed primarily to law enforcement, though the company
also makes its product available to selected other "investigators". It is
not clear if there is anyone, in fact, that the company will not
sell to, when asked.
Clearview argues that its product is a kind of search engine: you give it
a picture, and it finds a match. However, it is quite different from
Google's image search, which is intended only to find exact matches of a
given image. There is a tremendous amount of complex image analysis that
goes into finding a face match.
Perhaps the most controversial part of Clearview is how they got their
~3-billion-image dataset: they scraped it from the web. On Facebook, your
profile picture (which you do not have to include) is public, as is your
name. Clearview also scraped from Google, YouTube, Twitter, Venmo and
others, and from millions of personal web pages (which many people still
have, if only as a blog). This may violate the announced "Terms of
Service" of many of the sites, but those terms are only binding if you
have to accept them as a condition of accessing the site. (That might
be true of Facebook, which has sued Clearview for ToS violations.)
Clearview has stated it has a "first amendment right" to make use of the
facial data it has scraped. Legally, if they have a picture of you
together with your name, there is no clear legal argument for blocking
their use of it.
For an overall summary, see engadget.com/2020/02/12/clearview-ai-police-surveillance-explained.
Clearview's customer list was leaked in February 2020. Clients include
the Justice Department, ICE, and the Chicago Police Department (on a trial
basis). However, it has many commercial clients, presumably for either
customer profiling or for shoplifting investigation. These clients include
Wal*Mart, Best Buy, Macy's, Kohls and the NBA. See buzzfeednews.com/article/ryanmac/clearview-ai-fbi-ice-global-law-enforcement.
Before Clearview became well-known, it was widely available to wealthy
individuals and to corporations with little clear need for facial
recognition, as the company sought investors; see nytimes.com/2020/03/05/technology/clearview-investors.html.
See also "Your Face Is Not Your Own", www.nytimes.com/interactive/2021/03/18/magazine/facial-recognition-clearview-ai.html.
Tinder
The popular dating app Tinder keeps a large amount of potentially very
sensitive information about its users. In 2017, journalist Judith
Duportail invoked her EU right to her Tinder records. It amounted to 800
pages. She writes:
At 9.24 pm (and one second) on the night of
Wednesday 18 December 2013, from the second arrondissement of Paris, I
wrote “Hello!” to my first ever Tinder match. Since that day I’ve fired up
the app 920 times and matched with 870 different people. I recall a few of
them very well: the ones who either became lovers, friends or terrible
first dates. I’ve forgotten all the others. But Tinder has not. [www.theguardian.com/technology/2017/sep/26/tinder-personal-data-dating-app-messages-hacked-sold]
In particular, Tinder remembers all the messages. It is not just the
sexual ones that are revealing; people often say very personal things to
new partners, as part of establishing intimacy.
Tinder has not, as far as we know, yet been hacked. But what happens if when it is?
Should Tinder be subject to any special regulations concerning its stored
data? Should they be allowed to change the terms of service as applied to
past data? Should the current terms of service be binding on any
company that might purchase Tinder? What should the rules be for police
access?
Managing Your Online Privacy
The article linked to here is about the idea that younger adults --
so-called Generation Y -- might (or might not) be more aware about how to manage
their FaceBook privacy, and by the same token to be less strict about what
they expose online.
http://www.techrepublic.com/blog/security/whats-with-generation-y-and-online-privacy/9042
The article closes with these questions:
- According to studies, Millennials are more aware of how to control
their online reputations. Does that offset their allowing more access to
information deemed sensitive by older adults?
- It is almost assured what is released to the Internet is public
knowledge forever. Why does this scare parents and older adults, but not
Millennials?
- Do you think parents and older adults are alarmed at the openness of
Millennials because they feel Millennials are naïve about future fallout
from their openness online?
Some further things to think about:
1. Are younger people more likely to allow more access?
2. In a practical sense, is it really true that what's on the
Internet is there forever?
3. Are some people (perhaps older people) unnecessarily conservative about
online privacy?
Discussion
Joe the Plumber
aka Samuel Joseph Wurzelbacher
This is something of a parable of the problems with online public records
He went to an Obama rally and asked a serious question about Obama's tax
plan (in which he apparently confused income with profit). Obama made his
"spread the wealth" remark in response. After this was in the press, McCain
ran with it, and referred to him multiple times in the debate, as a symbol
of middle-America and small businesses.
One reporter (in a print newspaper column I failed to save) argued that
Wurzelbacher should have no
expectation of privacy. At what point does this become true? Is it true of
Obama? Was it true for Palin, or McCain? Wurzelbacher did try to capitalize
on his sudden fame, and some might argue that in doing so he lost his
expectation of privacy. But suppose he had tried to remain a private
citizen?
Allegations about him:
- no license (but he wasn't a contractor; he might
need a journeyman's license; this is unclear)
- back taxes: $1,182 to Ohio
- child support: Helen Jones-Kelly: director of Ohio Dept of Job &
Family Services, authorized a probably-illegal check on Wurzelbacher's
child-support payments. Julie McConnell, of the Toledo Police
Dept, was charged also. Apparently neither case went anywhere, but
Jones-Kelly later resigned.
- divorce records: 2006 income was $40K
- voter records: he's registered, but his last name was misspelled
"Worzelbacher"
- related to Robert Wurzelbacher (not!), son-in-law of Charles Keating
& convicted of Savings & Loan fraud; RW served 40 months in
prison
Lucas county clerk of courts: http://apps.co.lucas.oh.us/onlinedockets/Default.aspx
Search for "Wurzelbacher".
Is the availability of this kind of search
appropriate?
See also Baase, 4e §2.4.2 / 5e §2.4.3, on Public Records. Her examples
include:
- records on everyone who gave more than $100 to a political candidate
- records on flight plans of executive aircraft, as a way of tracking
the position of the CEO
- judges financial-disclosure forms. Formerly, you had to show your ID
to get access; now it's online. These forms show where judges' family
members work and go to school.
What of the above is legitimate to talk about for a private citizen?
At what point did Wurzelbacher stop being a private citizen?
Wurzelbacher asked Obama a financial question. Does this make W's income and
taxes fair game? What about his child-support records?
Aw, to hell with facts: see http://www.slate.com/id/2202480
Theories of Privacy
Is it obsolete? See Baase 5e Section 2.6.
Is it true that "young people of today" are not as concerned about privacy?
WHY?
Or did this change with Facebook etc?
Warren and Brandeis, 1890
See groups.csail.mit.edu/mac/classes/6.805/articles/privacy/Privacy_brand_warr2.html.
(Louis Brandeis later became a Supreme-court justice.) In a Harvard Law
Review paper, they argue for the principle of "inviolate
personality" that gives everyone specific rights regarding their
personal information. For them, privacy is the right "to be let
alone". Their primary concern was with publication of private
information by the press, especially by newspaper gossip columns. Their
argument was that repeating "private" information about someone violated a
fundamental right. Baase, 4e p 100 / 5e p 109.
Problems arise here because Warren and Brandeis did not formulate precisely
what was meant by an "inviolate personality", or to explain at what point
your rights to your inviolate personality give way to the Public's Right To
Know. For government officials, for example, the right of the voters to know
what they are really like might be very important.
Another issue is that WB seemed most concerned with publication
of data that violated our privacy. What if it is just made available to a
selected few? Employers? People on some committee at our church? Car-rental
agencies? People with some self-defined Need To Know, such as our annoying
neighbors? This is not normally understood to be publication.
Thomson, 1975
Judith Jarvis Thomson argued against the Warren-Brandeis position (www.eecs.harvard.edu/cs199r/readings/thomson1975.pdf).
Her paper begins "Perhaps the most striking thing about the right to privacy
is that nobody seems to have any very clear idea what it is." She goes on to
claim that every time a privacy right is violated,
there is in fact some other, more concrete, right being violated.
The implication is that we do not need special privacy rules. One of her
examples (section IV) is the Picture Scenario: if a man has a picture he
doesn't want people to see, he can keep it private. If they break into his
house, they have broken the law. If they view the picture remotely, using
X-rays, they have violated the man's property rights in
the picture. The man can waive this right if he displays
the picture publicly. If Alice interrogates Bob violently and thus obtains
Bob's private information, the real issue is the violence and not the
privacy invasion. If a company reveals information about you in a way that
is contrary to their own privacy policy that you accepted, they are
violating your contractual rights.
A less-clear example is the Shower Scenario: she argues that if someone
peeps at you while you shower, they have violated your "right
to your person" (section V). The same applies to her Marital
Argument scenario: if a couple doesn't want people to hear their argument,
they can close the window, at which point someone using eavesdropping
equipment to listen is violating this same right. Thomson felt the right to
ones person was, if anything, even stronger than the right to ones property.
But is this just a Warren-Brandeis-style privacy right, or is the "right to
your person" more concrete and limited?
Others have tried to find examples where your right to privacy was violated,
but no other rights were. What if someone reads your email? Are there other
rights involved besides your right to privacy?
Transactions
On 4e p 103 / 5e p 112, Baase describes a scenario involving Joe, Maria, and
some potatoes. Joe buys the potatoes from Maria; Maria sells the potatoes to
Joe. Who owns the information about the transaction? Either party might
want the information kept private; does the other party then have an
obligation to keep it so? Or does the privacy-concerned party have to add
that into the contract up-front, so that if Joe wants it private then he
might have to pay more, or if Maria wants it private then she might have to
charge less?
Who is the transaction about?
Another example is the making of "connections" visible to Everyone on
Facebook: which party is in charge here?
In the real world, sellers are often large corporations. When we as
individuals buy things, the balance of power is skewed in favor of the
larger seller. Does this change things?
Transaction privacy is a major conceptual underpinning of the legal
Third-party Doctrine: if someone else has access to a record, you do not
have a privacy interest in it.
Property Rights to Personal Information
Do we have such rights? What about "negative" information, such as
- tenant payment information or activism
- driving records
- credit information
One immediate issue is the transactions
one: is a tenant's late-payment history their
property, or the landlord's? Judge Richard
Posner (Seventh Circuit appellate judge who has written several
opinions involving economic arguments) has said that personal information
that is not "expensive" in the economic sense should receive more
protection.
Free-market privacy
[Baase 4e p 107 / 5e p 117] The argument here is that our information is
something we have a right to sell. We are informed consumers, and if we want
to sign up for a Shopper Surveillance Card, we have a right to. Similarly,
we have the ability not to share our personal information with websites that
do not have good privacy policies, and Baase has argued that many websites
have as a result of this become very interested in their privacy policies.
Or is it just that companies don't want the bad publicity that comes with a
bad privacy policy plus an
incident?
This approach to privacy means that we just accept that we can't get the
lowest prices and privacy, or we
can't get certain websites without
advertising, or certain jobs without
waiving our rights to certain private information, or use certain
social-networking sites without sharing some of our private information with
the world.
In terms of protection of our personal data in the hands of corporations,
this approach suggests that businesses will protect our data because they
don't want the liability that comes with accidental release. Specific
regulations are not necessary.
Our right to privacy here is the negative
right, or liberty, not to share our personal information.
Question: is it wrong to offer poor people the option of selling away their
fundamental rights? We do not, for example, allow poor people to sell their
kidneys, and we do not allow them to let their children go to work at age
14. We do not allow workers covered by Social Security to take the money and
invest it privately.
But we do allow better-off consumers to "sell" some of their privacy in
exchange for lower grocery prices; why should worse-off consumers be denied
this? Or should everyone be denied
this?
Consumer protection and privacy
[Baase 4e p 109 / 5e p 118] The alternative approach is that we need lots of
government regulations to protect ourselves, because we just can't keep
track of all the implications of revealing each data item about us. There
should be rules against keeping certain data, even
with our consent, because society can't be sure such consent is
freely given.
A central idea of regulations is that we are denied
the right to do certain things (eg sell some of our private information), on
the theory that most people will not understand the full scope of the
transaction, and there is no practical way of separating those who don't
from those who do.
Large corporations with our data have an unequal share of the power. We need
fundamental positive rights
that say others have an obligation to us not to do certain things with our
data (like share it).
This approach is likely to lead to an "opt-in"
requirement for use of private data, rather than an "opt-out".
Workplace privacy of email
One fairly basic principle the courts have used is whether or not one has a
"reasonable expectation of privacy". However, this doesn't always mean quite
what it seems.
Smyth v Pillsbury, 1996
Summary: Michael Smyth worked for Pillsbury, which had a privacy policy
governing emails that said Pillsbury would NOT
use emails against employees, and that emails "would remain confidential and
privileged". Specifically, Pillsbury promised that e-mail communications
could not be use against its employees as grounds for termination or
reprimand.
Smyth and his boss exchanged emails in which marketing employees were
discussed in an unflattering light. The phrase "kill the backstabbing
bastards" appeared.
Smyth and his boss got fired, based on the contents of their emails to each
other.
Smyth sued for wrongful termination. He
lost.
Bourke v. Nissan:
This was a similar California case: Bonita Bourke worked for Nissan. One of
her email messages was reviewed, somewhat accidentally, by management. It
was highly personal. Bourke received a low evaluation; this was mostly
likely due almost entirely to her email. She sued for invasion of privacy,
and lost, though the California state court of appeals did not "publish" its
decision, meaning it is not to be used as a precedent.
Shoars v. Epson: California
Alana Shoars was involved in email training at Epson. She found
supervisor Hillseth had been printing and reading employee emails. She
objected, and removed some of the printouts from Hillseth's office. She
also reported the incident to Epson's general manager, and requested a
private Epson email account not accessible by Hillseth. Hillseth then had
Shoars fired. Epson had informed employees that email was "private and
confidential". California had a law prohibiting tapping of telephone
lines. The law may have covered other communications, but that part was
dismissed on a technicality: tapping alone didn't constitute
eavesdropping, and the eavesdropping issue was never brought up.
Smyth v Pillsbury, 1996
Summary above
Federal District Court within Pennsylvania, 1996. Case was dismissed
after a preliminary hearing (not a trial).
The District Court opinion is at http://pld.cs.luc.edu/ethics/smyth_v_pillsbury.html.
Judge: Charles Weiner
Whatever happened to the contractual
issue? How could Pillsbury ignore an official written policy that emails
would not be used as grounds for termination or reprimand? Hint: there is
a long history of cases upholding "employment at will" doctrine. Still,
there is also a long list of situations where at-will employment is
protected:
- when the employee has contractual or union protections
- dismissal for refusal to do illegal acts
- dismissal for racial, ethnic, & religious discrimination (civil
rights act)
- dismissal for age discrimination
- whistleblower protection
- Americans with Disabilities Act protections
- employees were engaging in protected conversation about workplace
conditions
- employees object to offensive
conduct on the part of the employer
Judge Weiner simply did not think Pillsbury's conduct was offensive, or
offensive enough, to warrant
application of the last exception above. But parts of the decision suggest
Weiner was simply not very sympathetic to privacy concerns, and perhaps
did not entirely understand the case.
The case is a good example of how the "reasonable expectation of privacy"
doctrine can fail completely, if someone thinks you do not have such an
expectation. How can you argue that you do have a reasonable expectation?
One way to view this case is that Smyth simply sued for the wrong thing.
Reinstatement was governed by the at-will employment doctrine, and
requires a very high burden of proof. Financial damages for invasion of
privacy might have been another thing entirely.
Note that ownership of the email system does not
matter. Consider the following:
- ownership of a phone
- ownership of stationery
- ownership of an apartment building
None of these ownership categories give the owner the right to listen to
phone calls / read letters / snoop in apartments!
How would the case have been different if:
- Pillsbury had an email policy allowing supervisor access?
- Pillsbury had no policy at all?
Contract versus Tort:
If you harm someone with whom you have a contract, it falls under
contractual law. If you harm someone without a contract, it falls under
tort law.
Smyth was asking for application of the tort
of invasion of privacy to be applied. A "tort" is essentially a common-law
right that has been breached, as opposed to a contractual right. Tortious
invasion of privacy exists, but the standards are high and privacy must be
a reasonable expectation. Smyth was alleging that Pillsbury violated the
tort of substantial and highly offensive invasion of
privacy.
Judge Weiner, however, held that corporate eavesdropping is not
offensive. Period.
Arguably, the most offensive part of Pillsbury's intrusion was that it
was done despite the company having promised not to.
Weiner did not consider this. Does Pillsbury's promise here make their
surveillance offensive?
Or, to put it another way, did Pillsbury's promise give employees a reasonable
expectation of privacy?
Weiner said Smyth lost because email was "utilized by entire company"
and Smyth's emails were "voluntary". Neither of these points necessarily
changes the privacy issue, though. From the decision:
we do not find a reasonable expectation of
privacy in e-mail communications voluntarily
made by an employee to his supervisor over the company e-mail system
notwithstanding any assurances that such communications would not be
intercepted by management.
The use of the word "voluntary" is in contrast to mandatory urinalysis
cases; see below for further discussion. But note that all
communication would appear to be voluntary.
Weiner also stated above that employees do not have a "reasonable
expectation of privacy". He may have been overstating this, for emphasis; he
goes on though to clarify:
even if we found that an employee had a reasonable expectation of
privacy in the contents of his e-mail communications over the company
e-mail system, we do not find that a reasonable person would consider the
defendant's interception of these communications to be a substantial
and highly offensive invasion of his privacy.
That is, maybe Weiner might agree that in some cases one might
have a REoP regarding email, but regardless of that the interception of
email is not "substantial and highly offensive". A violation of a
"reasonable expectation of privacy" does not
mean the search is "offensive", and only searches that are "offensive"
would allow legal action regarding firing of an "at-will" employee. Weiner
is arguing here that the search did not even
violate a REoP, let alone rise to the level of being offensive. Weiner
might have been willing to compromise if the only issue had been some
degree of REoP, but that was not the issue at hand.
In other words, the Judge felt that Pillsbury's actions did not
tortiously (that is, in violation of some tort,
or general non-contractual duty) invade privacy.
An unstated justification for this is the prevention of sexual
harassment. This provides a legitimate "motive" for corporations to read
all employee email, though of course actual harassment can always be
reported by the recipient. But the recipient may be reluctant to complain.
The judge did state
Moreover, the company's interest in
preventing inappropriate and unprofessional comments or even illegal
activity over its e-mail system outweighs any privacy interest the
employee may have in those comments.
Arguably, though, the Smyth kind of talk between "buddies", with the
self-image projected to fit that context, is exactly what some
interpretations of privacy are about. Not all context is "professional".
What if Pillsbury recorded spoken water-cooler or bathroom conversation?
What is a "reasonable
expectation of privacy"??? "In the absence of a reasonable expectation of
privacy, there can be no violation of the right to privacy". (Bourke v
Nissan)
Could Smyth have sued for damages, instead of
reinstatement? Maybe. Could Smyth have sued for contractual
obligations? Only if he could convince the court that the employee manual
constituted a contract.
The judge essentially ignored Smyth's complaint that Pillsbury had
promised not to use the contents
of emails in disciplinary actions. Here is a footnote to his ruling:
["estoppel" is eh-STOP-uhl]
FN2. Although plaintiff does not
affirmatively allege so in his Complaint ... the allegations in the
Complaint might suggest that plaintiff is alleging an exception to the
at-will employment rule based on estoppel,
i.e. that defendant repeatedly assured plaintiff and others that it would
not intercept e-mail communications and reprimand or terminate based on
the contents thereof and plaintiff relied on these assurances to his
detriment when he made the "inappropriate and unprofessional" e-mail
communications in October 1994. The law of Pennsylvania is clear, however,
that an employer may not be estopped from firing an employee based upon a
promise, even when reliance is
demonstrated. [emphasis by pld] Paul v. Lankenau Hospital, 524
Pa. 90, 569 A.2d 346 (1990) [pld: summary below].
[Generally, estoppel means prohibiting ("estopping") a party to a lawsuit
from doing something they had promised not to do; in this case, firing
Smyth.]
In other words, this footnote states there is legal precedent for
rejecting a lawsuit for reinstatement that hinged on the fact that
Pillsbury had promised not to examine employee email. Smyth
was careful to phrase his argument in terms of invasion of privacy, but
perhaps the judge thought that was really just trying an end run around
this estoppel rule.
Here is a possible approach to Weiner's decision:
- The estoppel argument means that Pillsbury's promise not to eavesdrop
cannot matter, and so we can ignore this promise
- Once you ignore Pillsbury's promise not to eavesdrop, employees no
longer have a reasonable expectation that eavesdropping won't be done.
Is there a problem here?
Judge Weiner spelled out that exceptions to the employment-at-will
doctrine may only be made for compelling public-policy reasons; the
closest Smyth came to one of them was that Pillsbury's conduct was offensive. Smyth had claimed that
preventing violations of privacy would indeed be a sufficient
public-policy reason. Pennsylvania law defined a tort of "intrusion upon
seclusion" (not exactly the form of privacy Smyth was concerned with, but
close enough), but defined it to mean "intrusion [that] would be highly offensive to a reasonable person".
The judge then felt that Smyth's situation simply did not rise to this
level. In fact, the judge stated that Smyth did not even have a "reasonable
expectation of privacy".
Judge Weiner did make two somewhat unusual points about private communications.
First, as appears in a quote above, the email was voluntary
and Weiner writes:
[W]e find no privacy interests in such
communications.
What kinds of communication are involuntary? This would also seem
to strip email and telephone conversations of privacy rights. This sentence
can be read as meaning no forms of communication are subject to
privacy protections, because communication is always voluntary.
Second, Weiner also stated:
once [Smyth] communicated the alleged
unprofessional comments to a second person (his supervisor),... any
reasonable expectation of privacy was lost.
In other words, something is private only if you keep it
entirely to yourself; no transaction or communication with
another person can ever be private! Perhaps the judge had the
"third-party doctrine" in mind, but if so this is an odd application of
it.
Do you think this is an example of a case where the judge did not "get
it"? Or was Judge Weiner onto something? Or did he have a view of privacy
that was very different from freedom from surveillance?
Who decides when we have a "reasonable expectation of privacy"? If most
people think email privacy is easy to breach, does it lose
protection? Is this case about the judge not "getting it" that email
privacy is not about "whoever
owns the equipment can do what they want"? Is email any easier to spy on
than the phone?
So do we have a reasonable expectation of privacy in email for personal
use, if not in the workplace? Arguably more people do now than in
1996. Did a lack of understanding of email privacy back then saddle us with
the permanent idea that we had no reasonable expectation of privacy in
workplace email? Or was this inevitable, as soon as people had reasonable
alternatives for personal email?
The bottom line of Judge Weiner's ruling is that there is "no reasonable
expectation of privacy for work email" and they can read it even if they
promise not to. Alternatively, such a privacy invasion is not offensive
enough to warrant interference with the employment-at-will doctrine.
That "even if they promised not to" part fits in with longstanding law
regarding employment-at-will.
Paul v Lankenau Hospital
524 Pa. 90, 93, 569 A.2d 346,348 (1990)
(PA court Atlantic Reporter reference 2nd Series, vol 569
Starts page 346, actual reference on page 348)
Dr Parle Paul, MD, would take home discarded hospital equipment. He
would sell it or send it to clinics in Yugoslavia, his homeland. He got
permission to take five discarded refrigerators. Unfortunately, he
apparently did not have the RIGHT permission.
Oops.
He was fired, and filed suit in state court for reinstatement and for
defamation.
A jury trial resulted in a verdict in Paul's favor, both for damages and
reinstatement. Superior court affirmed. The appellate court reversed the
reinstatement order.
From the appellate decision:
Equitable estoppel is not an exception to
employment at-will. The law does not prohibit firing of an employee for
relying on an employer's promise.
Exceptions to the [at-will firing] rule have
been recognized in only the most limited circumstances, where discharges
of at-will employees would threaten clear mandates of public policy. [some
such: racial/ethnic discrimination, whistleblowing, refusal to commit
illegal acts, unionizing, ...]
In other words, the court ruled that Dr Paul's firing was not "offensive"
enough to warrant an exception, just as judge Weiner ruled regarding
Smyth.
According to this precedent, Smyth (and his lawyers) knew
that he could be fired for any reason, regardless of Pillsbury's promises
to the contrary. Pillsbury cannot be estopped
from firing him just because they promised not to.
In court cases, you can't add 30% of an argument for equitable estoppel
("hey, they promised!") and 70% of an argument for tortious invasion of
privacy ("they listened in!") to get 100% of a case. ONE argument must be
100% sound.
Jurisdiction and Privacy
What if one party to an email lives in a state that grants statutory
privacy protections? This problem comes up all the time with phone calls:
Worldcom case: Plaintiffs were Kelly Kearney
and Mark Levy; they worked for a company acquired by Worldcom. Their calls
were recorded in Georgia, but plaintiffs were calling from California,
which forbids recording without notification of ALL parties. They sued the
Georgia company that made the recordings, in California. They lost at the
trial-court and appellate-court levels, but the California Supreme Court
found in their favor, in principle.
The court found that recording of calls involving Californians that
violated California law could be prosecuted in California no matter where
the recording took place, but also declared that, because this was a close
issue, it would only apply to future cases.
Illinois law similarly makes it illegal to record a phone conversation
(or any conversation, until a
2012 Seventh Circuit decision) without the consent of all parties.
The California Supreme Court finally found in Kearney and Levy's favor,
but only granted an injunction prohibiting this behavior in the future.
Massachusetts case: jurisdiction depends on where
wiretapping physically took place, not where the speakers were. How does
telephony relate to email? What is
our expectation of privacy?
What about use of, say, a personal gmail account while at work? If
employer monitors transactions with gmail.com? If employer obtains email
from google directly?
Loyola policy: luc.edu/its/policy_email_general.shtml
(discussed below)
Persistence: email sticks around, although people traditionally use
it as if it were like the phone.
Loyola's policy on email
Policy until 2012:
Privacy on University electronic mail systems [1997-1998] http://www.luc.edu/its/policy_email_general.shtml
In the section subtitled "Privacy on University electronic mail
systems", seven reasons were given why someone else might read your email:
The University community must recognize that
electronic communications are hardly secure and the University cannot
guarantee privacy. The University will not monitor electronic mail
messages as a routine matter. But the University reserves the right to
inspect, access, view, read and/or disclose an individual's computer files
and e-mail that may be stored or archived on University computing networks
or systems, for purposes it deems appropriate. There may arise situations
in which an individual's computer files and e-mail may be inspected,
accessed, viewed, read and/or the contents may be revealed or disclosed.
These situations include but are not limited to:
- During ordinary management and maintenance of computing and networking
services,
- During an investigation of indications of illegal activity or misuse,
system and network administrators may view an individual's computer
files including electronic mail,
- During the course of carrying out the University's work, to locate
substantive information required for University business, e.g.,
supervisors may be need to view an employee's computer files including
electronic mail,
- If an individual is suspected of violations of the responsibilities as
stated in this document or other University policies,
- To protect and maintain the University computing network's integrity
and the rights of others authorized to access the University network.
- The University may review and disclose contents of electronic mail
messages in its discretion in cooperating with investigations by outside
parties, or in response to legal process, e.g., subpoenas,
- Should the security of a computer or network system be threatened
Current policy
Official E-Mail-Voice Mail Use and Disclosure Policy: luc.edu/its/policies/policy_email_voicemail.shtml
Some more general guidelines for email use: luc.edu/its/itspoliciesguidelines/policy_email_general.shtml.
Confidentiality of electronic mail
From the first policy:
Loyola cannot guarantee the confidentiality or
privacy of electronic or voice mail messages and makes no promises
regarding their security. Decisions as to what information to include in
such messages should be made with this in mind. The following elements
guide the administration of electronic and voice mail at Loyola as it
relates to confidentiality:
1. Administrative Activities: Loyola
reserves the right to conduct routine maintenance, track problems, and
maintain the integrity of its systems. As is the case with all data kept
on Loyola's computer systems, the contents of electronic or voice mail
messages may be revealed by such activities.
2. Monitoring: Loyola does not monitor the contents of electronic or voice
mail messages as a routine matter. However such monitoring may be
conducted when required to protect the integrity of the systems or to
comply with legal obligations.
3. Directed Access: Loyola does reserve the right to inspect the contents
of electronic and voice mail messages in the course of an investigation
triggered by indications of impropriety or as necessary to locate
substantive information that is not more readily available by some other
less intrusive means. Loyola will comply with all legal requirements for
access to such information.
Some possible protections (not actually implemented):
Protection against 1: If your email is examined accidentally or as part
of routine system maintenance, any contents implicating you on any matters
will not be held against you (exceptions???)
Protection against rule 2: If your email is examined because of concerns
about system integrity, any contents implicating you on other matters and
associated with your legitimate use of your account will NOT be held
against you (except in cases of ????)
While these would not be enforceable for staff, as at-will employees, they would be for
- students: really customers
- faculty: if tenured (that is a contract)
The new policy is definitely more focused!
Google Privacy Policy
Google changed their privacy policy on March 1, 2012. What does this mean?
For one thing, it means Google now has just one privacy policy, instead of
50+.
For another, it means that Google can use your search history when targeting
ads at you in Gmail/Google+/Google_Earth, etc. They've long used not only
your current search but also your search history when targeting ads for you
from within Google's search site. Arguably this is the main issue with the
change: all the data collected by Google as you interact with any Google
product can be pooled and used from any Google site.
Google does allow users to block the use of their Google-search data (in
Google Web History). You can also log out of your Google account before
searching.
Online Privacy and Advertising
The Amazing Dave: https://www.youtube.com/watch?v=F7pYHN9iC9I
Why are advertisers so determined to spy on you? Didn't print and television
advertising succeed without knowing much at all about the viewers?
An excellent summary of the history of online advertising is found in the
article The
Internet's Original Sin, by Ethan Zuckerman, now at MIT and
once the developer of the first pop-up ad:
Along the way, we ended up creating one of
the most hated tools in the advertiser's toolkit: the pop-up ad. It was a
way to associate an ad with a user's page without putting it directly on
the page, which advertisers worried would imply an association between
their brand and the page's content.
Here are a couple amazing numbers from Facebook in 2014:
| profit per user |
60 cents |
| time spent per user |
60 hours |
Facebook, in other words, makes one penny for each hour its users spend
online. (This may be a little low; Facebook's 2014 annual advertising
revenue (not profit) was around $20-30 billion)
(FB's profits continue to grow. FB's Annual Revenue Per User for North
America in the fourth quarter of 2019 was $40; the total revenue
for 2019 was about $70 billion)
So what works in online advertising? Zuckerman's next point is debatable,
but it's a good first approximation:
Targeting to intent (as Google's search ads
do) works well, while targeting to demographics, psychographics or stated
interests (as Facebook does) works marginally better than not targeting at
all.
But the takeaway for advertisers (and the websites supported by them) is
that if only we had a little more information about our users,
targeted advertising would finally get its big break.
C is for Cookie
Standard browser cookies consist of ⟨name,value⟩ pairs, each associated with
a domain (eg luc.edu). Both name and value are provided by
the website; cookies do not contain your own personal information.
Cookies may also have an expiration date. If there is no date then the
cookies are deleted when you exit your browser and are called session
cookies; cookies with expiration dates are thus persistent
cookies.
Secure cookies have a bit set that
limits access to secure (https) connections.
All these are forms of HTTP cookies. A specialized form of cookie is the
HttpOnly cookie; these can be requested by the server but not accessed
through javascript. This reduces the threat from so-called cross-site
scripting.
Accessing cookies: in theory a page
from domain foo.org can only access cookies sent from a host matching
*.foo.org. Mostly this is correct, though there are some peculiarities of
domain naming that make this not completely secure. For example, a host
under the control of foo.org may have name bar.com; alternatively, DNS
cache poisoning may make host bad.com appear to be good.foo.org.
Another threat is top-level-domain cookies. Browsers disallow the use of
.com or .org as a cookie's domain, because then bad.com could set one that
might interfere with cookies from good.com. However, the list of
top-level-domains keeps growing, and only the most up-to-date browsers will
recognize all of them.
Cookies were introduced to provide stateful
browser sessions, eg for a shopping cart or an authenticated login.
Every time the server sends you a page, it can first retrieve its cookies,
which identify you and thus identify your shopping cart or the fact that you
are logged in. Alternatives to cookies for stateful browsing include long
dynamic URLs.
Another use for cookies support of site personalization.
If you make some settings and expect them to be present the next time you
return, it is cookies that make this possible.
Persistent cookies also enable automatic login, eg to facebook.com after you
restart your browser. Persistent cookies, however, also enable support for tracking. Originally this meant tracking
you as you returned to the site, so that the site managers could tell how
many people returned multiple times; the original argument that cookies
couldn't be used to track you across multiple sites was based on the idea
that site foo.com could not request the cookies set by site bar.com.
However, nothing prevents sites foo.com and bar.com from sharing information
about visitors.
Browsers have allowed users from the late 1990s to refuse to accept cookies,
or to accept them selectively. Generally, however, this makes sites either
completely unusable (eg shopping sites) or practically unusable (eg because
of the need to click OK incessantly).
Third-party cookies are cookies from
a site other than the one in the location bar (either typed by you or from a
link). They arise from some embedded component (image or frame) from the
third-party domain, or simply because the site (eg loyolaramblers.com) had
an affliated or parent corporation (eg luc.edu) send a cookie. When the
third party is advertising.com, or doubleclick.net, or adwords.google.com,
they may be on a lot of other pages as well.
It is third-party cookies that are the dangerous ones, as these can tie
multiple web pages together.
Originally, third-party cookies were used to limit popup ads to one per
visit, or to show ads in a particular sequence, or to audit the ads. But now
advertisers use cookies to string together the sequence of pages you've
visited. Or at least that your browser session has visited.
There are also other types of cookies; for example, there are flash
cookies sent when you visit sites with embedded flash content, and
Document Object Model (DOM) cookies.
Adobe provides an online Settings Manager at http://www.macromedia.com/support/documentation/en/flashplayer/help/settings_manager07.html.
This is, officially, the only way to remove flash cookies, though on my
linux system they are in domain-named subdirectories of
$HOME/.macromedia/Flash_Player/macromedia.com/support/flashplayer/sys, and
on winXP they appear to be in C:\Docs&Sets\%USER%\Application
Data\Macromedia\Flash Player\#SharedObjects\*\.
The term zombie cookies refers to
cookies that are recreated (as HTML cookies) from scripts, based on data
found in DOM and Flash cookies. This seems a little intrusive; zombie
cookies are a clear violation of the user's expressed intent.
Where are your cookies? Where are
your flash cookies (*.sol files)? How do you get rid of them?
dictionary.com is famous for installing
flash cookies, but in my own test the site just installed three or four.
Plus some number of regular cookies.
It seems clear that the only reason advertisers use flash and DOM cookies is
to get around users who delete cookies regularly, or who use
anti-advertising tools. But see also panopticlick, below.
You can use the tool at simonhearne.com/2015/find-third-party-assets
to identify third-party domains, and thus potential cookie suppliers.
Third-Party Cookies
Firefox has now provided tools to block these, though they apparently are
still enabled by default. See http://blog.mozilla.org/privacy/2013/02/25/firefox-getting-smarter-about-third-party-cookies/.
If third-party cookies are not supported, however, that does not end
tracking. If you go to loyolaramblers.com and there's an ad from
doubleclick.net, then without third-party cookies doubleclick.net can't
send you one. One option is for doubleclick.net to be promoted to a
first-party participant on the site; that is, it would appear to Firefox
that you visited them.
Here's how to disable these in Firefox. Go to Preferences → Privacy and
Security → History → Accept third-party cookies. Think about setting this
to "Never".
(See also Tracking Protection in the same section.)
For more browser privacy settings, see gist.github.com/haasn/69e19fc2fe0e25f3cff5.
Targeted Advertising
What advertisers really want (or
think they want) is to display ads on your pages that are related to your
interests. To this end, so-called "ad tech" attempts to find out as much as
possible about your interests, both short-term and long-term. Facebook is a
master at discerning your long-term interests; so is Google, by analyzing
the kinds of things you search for.
But advertisers are also happy with short-term interests (and Facebook and
Google both excel here too). One thing they try to do is to create ads that
track you (or at least your interests) across sites. So that if you go to
vw.com to look at cards, and then to cnn.com, the latter will show you ads
for VW (hopefully immediately, but at least eventually).
This is so important to advertisers that it has largely taken over the
industry; clicks may pay twice as much if you can show the client that the
user has clicked previously on related content. Industry wants ads that follow you around as you browse.
For this reason, when you go to a site with forms, or with a search engine,
the site may share with its third-party advertisers some information about
what you have typed in. Generally they do not
share names, addresses, or email addresses, but search content (or what
products you looked at) is generally fair game. For conventional consumer
products this is a no-brainer. If you go to a medical site, the site may
share your interest in arthritis remedies with advertisers, but perhaps not
your interest in herpes or bipolar disorder. But there are no guarantees.
Google does not share what you enter in the google.com search box with
third-party advertisers, but only because there are
no third-party advertisers: google is a first-party advertiser.
Here's the question: do you care?
In the WSJ article cited below, an ad executive makes the statement
When an ad is targeted properly, it ceases
to be an ad, it becomes important information
If the information's use was restricted to more advertising, would any
amount of information really matter? Or are there advertising approaches
that, by "knowing what strings to pull to get you to buy", are
fundamentally unacceptable? Or is it simply that you don't want ads for
alcohol showing up at routine sites, or for ads for a birthday surprise for
another family member showing up when that family member had a turn on the
shared computer?
And is there a special concern if this kind of information became available
directly to interested parties? For example, if employers could look up your
magazine subscriptions? Or get a general report on your browsing habits?
(This could happen only if the sites were very sure of your identity.)
The Wall Street Journal ran a series of articles documenting this
ads-following-you-around phenomenon; it is at http://online.wsj.com/article/SB10001424052748703940904575395073512989404.html.
With the cooperation of Lotame Solutions, an advertiser, the cookie ID of
Ashley Hayes-Beaty, 4c812db292272995e5416a323e79bd37, describes her as
enjoying
- The Princess Bride
- 50 First Dates
- 10 Things I Hate About You
- Sex and the City
But Lotame did not have Hayes-Beaty's name,
apparently, until the WSJ story.
The Journal also makes the claim (http://blogs.wsj.com/digits/2010/07/30/analyzing-what-you-have-typed)
that Lotame has website additions ("beacons") that can actually read what a
user types into text fields not "owned" by Lotame. It is not clear if this
is actually true, but if it is, it means that advertisers can harvest your
name, email address, passwords and any credit-card information. No technical
details are provided, but see http://insanesecurity.info/blog/javascriptuserscript-keylogger.
Arguably, keystroke logging is
illegal, under the ECPA.
Concerned users should consider installing noscript.
Experiment: with a "clean-slate"
browser, go to a car site (eg vw.com or pontiac.com),
and then to one of cnn.com / msn.com
/ chicagotribune.com. The goal is
to see if any ads follow you.
Can they get your name?
Sometimes it is easy to believe that, while sites know pretty much your full
browsing history, they at least don't actually have your name. In the Wall
Street Journal series (see previous notes), Lotame Solutions knew everything
about Ashley Hayes-Beaty except her name.
But sometimes they can get that too. If you go to site X and log in with
your real identity, X knows who you are. X's page may also have subobjects
from advertising site Y, who sends you a cookie and has you in their
tracking database. X may now agree to share your name with Y, and at this
point your name is likely everywhere. If Y is facebook.com, your name is
known without sharing.
Or perhaps X does not share your name with Y, but Y shares your browser
history with X. In this case your name may not be everywhere, exactly, but
X has everything about you.
During Covid, many restaurants started using QR codes
on menus: patrons would scan the menus with their phones, and order
online. This gave restaurants access to real-name information (assuming
electronic payment), and allowed the restaurant to place cookies. Worse,
sometimes the QR site was owned by a third party, which can now track you
via those cookies as you visit multiple restaurants. This (name,cookie)
information can be sold widely, as well. There are phone-based payment
apps, but these typically try to ensure some privacy. See www.nytimes.com/2021/07/26/technology/qr-codes-tracking.html.
QR codes can also contain embedded information identifying where the code
was displayed (though only for individually printed codes). Finally, a QR
code is basically a URL, except that QR codes can be used to direct people
to sketchy websites without the users being easily able to look at the URL
beforehand.
Location information
Many apps request this. But it is scarily intrusive. With location data,
it's easy to tell where you live, where you shop, where you work, who your
real-life friends are, what protests you attended, what bars you went to
and how late you stayed, who you sleep with, where your kids go to school,
and much more. And there's a big marketplace for it; see themarkup.org/privacy/2021/09/30/theres-a-multibillion-dollar-market-for-your-phones-location-data.
Weather apps are notorious for collecting location data. The app "needs"
your location to figure out your local weather report. But it also tracks
you pretty much continually, minute by minute.
What do they do with this data? Mostly mundane stuff. Stores, for
example, want to get a summary of who has come into the store, and what
their income and lifestyle are. This means, of course, that your own
location data must be correlated to your own income and lifestyle first
(though that can easily be done with the location data alone!).
Muslim Pro
The app Muslim Pro is widely used
to track the five times for daily prayers; it is used by Muslims
worldwide. I installed it on my android phone; when started, it
immediately said
The app needs your location to calculate accurate
prayer times
Of course, that meant enabling location on the phone, and also granting
that permission to the app. The app does have an option to work
without location data, but it's definitely something one has to search
for. The location data, of course, is used to determine the time of
sunrise and sunset.
It turns out that someone is buying this location data generated by the
app: the US military.
See https://www.vice.com/en/article/jgqm5x/us-military-location-data-xmode-locate-x.
The developer, Bitsmedia, by default shares information with a
"data-broker" company named Tutela, and a data broker named Quadrant. From
the Bitsmedia privacy policy:
Bitsmedia partners with Quadrant to collect
and share precise location information via mobile SDKs.
You can supposedly opt out of their reselling of the data. But if you do
not, Quadrant apparently sells your location data to a company named
X-Mode, who in turn sells it to the US army.
Again, a big issue here is that Android does not support different levels
of location data. There's a big difference between location data accurate
enough to determine the approximate time of sunrise and location data
accurate enough for a drone strike.
The Muslim Pro app does not directly obtain real-name information, but
location data is extremely hard to anonymize effectively.
In January 2024, X-Mode entered into a consent agreement with the FTC,
agreeing not to sell "sensitive" location data, with the burden on X-Mode
to correctly determine what was sensitive (clinic visits, for example).
See www.ftc.gov/news-events/news/press-releases/2024/01/ftc-order-prohibits-data-broker-x-mode-social-outlogic-selling-sensitive-location-data.
Monsignor Jeffrey Burrill
Father Burrill, then General Secretary of the US Conference of Catholic
Bishops, was outed as gay in 2021 by a Catholic group known as The Pillar
(www.pillarcatholic.com).
Apparently The Pillar purchased a dataset of user location information
originating from the same-sex hookup app Grindr. From www.pillarcatholic.com/p/pillar-investigates-usccb-gen-sec:
According to commercially available records
of app signal data obtained by The Pillar, a mobile device
correlated to Burrill emitted app data signals from the location-based
hookup app Grindr on a near-daily basis during parts of 2018, 2019, and
2020 — at both his USCCB [US Conference of Catholic Bishops] office and
his USCCB-owned residence, as well as during USCCB meetings and events
in other cities.
Such datasets are widely available from data brokers such as those above,
and that is unlikely to change soon as gay men are a major marketing
target. The data is nominally "anonymized", meaning that user names are
not attached. Generally speaking, such apps require user-location
information in order to match users to others nearby. The dataset included
timestamps; The Pillar and its collaborators then tried to match, for each
user in the dataset, whether the locations matched the known locations of
Catholic clergy at certain times, such at their homes during the evening.
Most records would yield no matches, but costs for the matching were still
pretty close to zero. See more at slate.com/technology/2021/07/catholic-priest-grindr-data-privacy.html.
It appears that The Pillar was approached by someone who had figured out
how to do the data analysis. Likely more than one priest was outed by the
data, but Msgr Burrill was the most high-profile, and the only one
publicly outed. See www.theatlantic.com/ideas/archive/2021/08/catholic-priest-jeffrey-burrill-grindr-pillar/619758.
The Pillar definitely tried to tie Msgr Burrill's sexuality with child
abuse. The argument was along the lines of "if he breaks his vows with
other adults, why should we believe him when he says he is not attracted
to children?"
Burrill filed suit against Grindr in 2023 or 2024, but success hinges on
Grindr not having disclosed their sales of location data. But they
probably did disclose it, in all that online fine print that few
read.
Sometimes location data is used for relatively anonymous
purposes: one standard technique is to identify people who, after being
shown a certain store-related ad, went to the store that was being
advertised. That kind of analysis can be done without selling the raw
location data. But there are still plenty of sellers of such raw data.
In 2023, the Washington Post (www.washingtonpost.com/dc-md-va/2023/03/09/catholics-gay-priests-grindr-data-bishops)
reported on a second group, Catholic Laity and Clergy for Renewal (CLCR, clcrenewal.com), who has also gotten
into the business of buying location information of Catholic priests in
order to out those who might be gay. The middle item on their mission
summary is "[to] provide evidence-based resources to bishops that enable
them to effectively judge and support quality formation practices" (that
is, formation of the clergy). CLCR claims it releases this information
only to the appropriate bishop, not to the public.
CLCR has, according to the Post article, purchased location data from
data brokers that was generated by users of Grindr, Scruff, Growlr and
OkCupid; the Post gives a total expenditure on this data of somewhere in
excess of $4 million. The same cross-referencing strategy used for Burrill
continues to be used; location data is trivial to deanonymize. Allegedly
twelve "suspicious" cases have been forwarded to bishops.
CLCR president Jayd Henricks posted a justification of his group's
strategy at www.firstthings.com/web-exclusives/2023/03/working-for-church-renewal.
The essay begins by discussing Cardinal McCarrick, who was removed from
ministry in 2018 due to substantial allegations that he had sexually
abused minors. Before 2018, and dating back to 1993, were allegations that
McCarrick had had sexual relationships with adult seminary students. But
the sexual activity uncovered by CLCR does not likely involve minors. Here
are some quotes from Henricks' essay:
In turn, a group of Catholics explored ways
in which the laity might better assist bishops to identify healthy
environments for priests and models to allow parishes and dioceses to
flourish, while helping to spot dangers that could lead to more scandal
and heartache for the Church down the line.
After all, data is used by all major corporations, so why not the
Church? Perhaps data could be used to gain insight into the life of
the Church, such as what sorts of church activities draw people to a
parish, or even when and how liturgies are scheduled.
Here's the Post's discussion of how the deanonymization process works.
CLCR data analysts
focused on devices that spent
multiple nights at a rectory, for example, or if a hookup app was used for
a certain number of days in a row in some other church building, such as a
seminary or an administrative building. They then tracked other places
those devices went according to location information and cross-referenced
addresses with public information
Match Group, owner of OkCupid, states that "[shared] location
data is obfuscated within a kilometer for safety reasons", although it is
not clear that is stufficent to prevent deanonymization of people who
travel.
In principle, these techniques could be used to target LGBTQ
church members, though the location data is relatively
expensive.
In 2019, Mike Yeagley -- a security-research consultant for the
US government -- started giving presentations about the Grindr location
problem to various government agencies. Yeagley bought the data, and
checked to see which people spent most of their workdays in government
office buildings. He then checked where else those users went. Finding
where they lived, and thus likely who they were, was similarly easy.
[Byron Tau, 2024] Yeagley used the Grindr data because, to the government,
it was still controversial.
Grindr was purchased by a Chinese company in 2016, but was sold
back to a US company in 2020.
A
good TIME Magazine article about online tracking. This article has
more examples of wrong or misleading information in advertiser/tracker
databases. Note that some tracking is "soft" (tied only to our computer, and
based on browsing history) while some is "hard" (specific business records
involving our name/address or ssn or both).
Microsoft and IE10 privacy settings: MS has decided to make "do not track"
the default in IE10. Advertisers, naturally, are upset.
http://www.geekwire.com/2012/microsoft-holds-ground-big-advertisers-blast-ie10s-default-privacy-settings/
Targeted Advertising Considered Harmful
That's the title of an article http://zgp.org/targeted-advertising-considered-harmful/,
written by Don Marti. The core of Marti's theory is that essentially nobody
trusts ads at face value. The one piece
of evidence we do have as to the trustworthiness of advertisers is
the money they spend. Full-page ads in upscale magazines, or television ads,
are not cheap, and the very existence of such an ad campaign means that
whoever is selling the product has reasonably deep pockets.
This kind of reasoning was analyzed by economist George
Akerlof, who observed that someone selling a car knows much more about
its condition than a prospective buyer. This "information asymmetry" also
holds for advertisers. One way we try to equalize the asymmetry is through
evidence of expenditures.
Under this theory, advertising should be most effective not when
it is targeted, but in fact when the opposite is true: when the
advertising appears on a reputable (hence expensive?) site.
It is not clear the extent to which this theory has been tested in the real
world. But even nontechnical computer users have started installing
ad-blocker software, so something has to give.
Browser Fingerprinting
Check out https://panopticlick.eff.org.
They don't need cookies to track you!
What do you think can be done about this? What aspects of the
fingerprint here contribute the most to identifying you? Can they be
disabled? Browser fingerprinting tends to get most of its information from
your installed extensions and fonts list, but lots of other sources do
contribute.
Browser fingerprinting is not all bad; it is used by banks, for example,
to keep track of whether you're using the same browser you've used before.
A change might trigger their asking one or more auxiliary security
questions.
For a good overall discussion, see pixelprivacy.com/resources/browser-fingerprinting.
Ad Blocking
Baase 5e has a new section (2.5.3) on ad blockers. The core question: are
they ethical? The argument against ad blocking is that ads are what pay for
almost all free journalistic content out there. If the difference between
filesharing (bad?) and radio (good) was that the latter has ads, then do we
in fact have some obligation to leave the ads in place.
For a Utilitarian approach, we start with the tradeoffs. Lost ads may mean
loss of free content (and we may miss out on discovering products that we
could really use!). But the gorilla in the room is that ads are not just
passive displays: we are actively being tracked with them.
Is there a deontological obligation to refuse to block ads? If not, why is
listening to the radio (or Spotify) ok, but filesharing is not?
It is harder (but not impossible) to block ads from Facebook because their
content and their ads come from the same source. At some point websites may
become the source of the ads they display as well, to make ad-blocking more
difficult.
Target and Pregnancy
Here's a link to Charles Duhigg's New York Times article: http://www.nytimes.com/2012/02/19/magazine/shopping-habits.html?_r=1&pagewanted=all.
The issue was this:
... once consumers' shopping habits are
ingrained, it's incredibly difficult to change them. There are, however,
some brief periods in a person's life when old routines fall apart and
buying habits are suddenly in flux. One of those moments -- the
moment, really -- is right around the birth of a child....
If Target could figure out how to identify pregnant women early on, earlier
than anyone else, they might be able to "lock them in" as long-term
customers. So Target statistician and marketer Andrew Pole was assigned the
task. He pretty much succeeded. One flag turns out to be purchases of larger
quantities of unscented lotion; another is dietary supplements.
Pole presumably figured this out by identifying women who had recently had
babies, through the usual way of consulting birth records, and then going
back to look at what they had been purchasing three, four and five months before delivery.
Target's second problem was how to make use of this; customers who received
baby ads early in their second trimester were likely to take offense. So
Target mixed in baby ads with ads for kitchen stuff, lawn & garden
stuff, towels, and everything else. But the baby products were carefully
chosen. And the ads -- individually prepared but designed to look
mass-produced -- might also include those products that the woman was known
to be already purchasing at Target.
At some point, Target got cold feet about Duhigg's article and forbade Pole
to speak further.
Duhigg's article contains a famous anecdote: that one father objected to his
teenage daughter's receiving baby ads from Target, only to find out later
that his daughter was pregnant. This story is probably fictitious;
see here.
(This incident may be why Target told Pole not to talk to Duhigg.)
You can see Andrew Pole giving a presentation on Target data analytics here, or go here
and follow the links.
Flash forward seven years, the sentence below appeared in this article: newyorker.com/magazine/2019/06/03/parenting-by-the-numbers:
At the same time,
Big Data is increasingly sinister. If you’ve been pregnant lately, you’ve
undoubtedly had the eerie experience of seeing baby-related ads popping up
online before you’ve shared the news with anyone.
This may simply be selection bias: people are much more likely to notice
baby ads after learning they are pregnant. But it might also be
based on searching for baby stuff, or pregnancy-related information. Or
even based on location tracking, after someone has visited an
obstetrician.
Hiding Your Pregnancy
Pole did his work around 2010; Duhigg wrote about him in 2012. In 2014,
Janet Vertesi tried very hard -- and mostly successfully -- to hide her
pregnancy from Big Data. Read about her story in How One Woman Hid Her
Pregnancy Form Big Data, mashable.com/archive/big-data-pregnancy.
(See also time.com/83200/privacy-internet-big-data-opt-out).
She had to unfriend some family, and even ran into rules mandating the
reporting of suspicious bank transactions. Consider this observation:
According to Vertesi, the average
person's marketing data is worth 10 cents; a pregnant woman's data
skyrockets to $1.50.
That explains a lot of Pole's motivation! I'm sure the dollar value is
more now. A report quoted by Vertesi says that
Identifying a single pregnant woman is worth
as much as knowing the age, sex and location of up to 200 people
(I am not so sure if it is accurate to include location data; that data
has become much more valuable in recent years.)
Jia Tolentino repeated Vertesi's experiment in 2022, and recounted her
progress in www.newyorker.com/culture/the-weekend-essay/the-hidden-pregnancy-experiment.
Tolentino was quite successful until her sixth month, when she abruptly
dropped the project: "I congratulated myself by instantly dropping the
experiment and buying maternity pants; ads for baby carriers popped up on
my Instagram within minutes." But, up to then, she had been shown no
baby-related ads.
Life Insurance
Car insurance companies figured out ~20 years ago that credit reports were a
remarkably good predictor of driving risk; most automobile-insurance
underwriting now uses these reports.
Now it's the turn of life insurance.
See http://online.wsj.com/article/SB10001424052748704648604575620750998072986.html.
The goal was to replace traditional blood & urine screening (which costs
close to $100 to do) with data mining.
Regulators are concerned; one points out that a subscription to a magazine
about a high-risk activity (the example in the article is "Hang Gliding
Monthly") may be linked to dangerous behavior but also may be simple
entertainment. However, if the data-mining results were used only to exempt
people from the medical screening, it might be ok.
Here's a core example from the article:
Using readily available data, the consultant said, an insurer could
learn that "Beth" commutes some 45 miles to work, frequently buys fast
food, walks for exercise, watches a lot of television, buys weight-loss
equipment and has "foreclosure/bankruptcy indicators," according to
slides used in the presentation.
"Sarah," on the other hand, commutes just a mile to work, runs, bikes,
plays tennis and does aerobics. She eats healthy food, watches little TV
and travels abroad. She is an "urban single" with a premium bank card
and "good financial indicators."
Deloitte's approach, the consultant said, indicates Sarah appears to
fall into a healthier risk category. Beth seems to be a candidate for a
group with worse-than-average predicted mortality. The top five reasons:
"Long commute. Poor financial indicators. Purchases tied to obesity
indicators. Lack of exercise. High television consumption indicators."
What do you think of this data? Which of it may have come from grocery-store
surveillance cards?
Should medical insurance
companies have access to this data?
Automobile insurance companies are
working hard at using this kind of data to figure out which drivers
(especially younger drivers) are the better risks. Here's an article (thesun.co.uk/motors/5401901/admiral-hikes-insurance-costs-for-drivers-using-hotmail-email-addresses)
suggesting that the UK's Admiral Insurance charges more for users who list
hotmail email accounts vs gmail.
That leaves home insurance as an
area where, so far, the risk seems unrelated to your online life.
gmail
All gmail is read at google. Just not necessarily by people. Does
this matter? (Google is currently being sued about this;
see http://articles.washingtonpost.com/2013-09-26/business/42421388_1_gmail-users-google-s-marc-rotenberg.
The case led Google to declare that gmail users do not have a
"reasonable expectation of privacy". However, in March 2014 the plaintiffs
were denied class-action status, meaning the suit is unlikely to
continue.)
Note that gmail has access to the full text of your email itself. This
means Google knows more about you than any regular web advertiser, with
the possible exception of Facebook (which tends to have slightly different
information).
What if Bradford Councilman, of the email-scanning scheme, had had
automated software read the email, and this software then updated
Councilman's book-pricing lists? Is this different from what gmail does,
or the same?
What if Google searched gmail for insider stock tips, and then invested?
What could Google do with the
information it learns about you? What could they do beyond learning of
your areas of interest?
What could the government do, if they had access to all your email?
Once Upon A Time, some people laced their emails with words like "bomb" and
"terrorist", intended as a troll for the NSA. If you're doing that today
you're most likely trolling gmail instead of the NSA. Try lacing your google
email with words related to a single hobby with substantial commercial
presence (eg tennis), and see what ads you get. (Perhaps the most
interesting test would be to choose a socially stigmatized hobby.)
- to detect criminal activity
- to detect hacking targeting the ISP
- to detect protests about lack of "net neutrality", and slow down your
service as retribution?
RFID
Original reading: Simson
Garfinkel, Adopting Fair Information
Practices to Low Cost RFID Systems.
RFID (Radio Frequency IDentification) tags were, for a while, considered
to be a looming new privacy threat. Now very few people worry much about
them. At this point we are looking at them as an example of a
privacy-threatening technology that has not come to much. Why is
that?
"Active" RFID tags -- more accurately called devices -- are
things like cellphones and iPass transponders that enter into radio
communication with outside receivers.
"Passive" tags are like the chip in a CTA Ventra card or other
contactless payment card or in your Loyola ID card. They are activated by
being in the presence of a radio field, which (very) temporarily powers
them up.
Some stores (notably Wal*Mart) have pushed to have everything in the
store delivered with an RFID tag. The tag would be like the usual
inventory/shoplifting tag, but it could also do the following:
- Allow merchandise to "tell" stockers exactly where it should go
- Greatly expedited one-pass checkout
- Shoplifting detection
- act as a receipt after the sale
Consider RFID and bar codes. In one sense, both types work by being
"illuminated" by a source of electromagnetic radiation. In practice, most
ordinary materials are not opaque to RFID frequencies, and more
information can be stored.
creeping incursions: when do we take notice? Is there a feeling that
this "only applies to stores"? Are there any immediate social
consequences? Is there a technological
solution?
How do we respond to real threats to our privacy? People care about SSNs
now; why is that?
Are RFID tags a huge invasion of privacy, touching on our "real personal
space", or are they the next PC/cellphone/voip/calculator that will
revolutionize daily life for the better by allowing computers to interact
with our physical world?
Imagine if all your clothing displays where you bought it: "Hello. My
underwear comes from Wal*Mart"
(Once upon a time, RFID chips didn't take well to laundering, but this has
changed; hotel towels now often have embedded RFID chips to discourage
theft. See http://jerrygamblin.com/2016/03/01/please-scan-my-towel/.)
RFID tags on expensive goods, signaling that I have them: iPods,
cameras, electronics
Loyola RFID cards
RFID v barcodes: unique id for each item, not each type readable
remotely without your consent
"Kill" function
Active and passive tags
Are there ways to make us feel better about RFID??
Garfinkel's proposed RFID Bill of Rights:
Users of RFID systems and purchasers of products containing RFID tags
have:
- The right to know if a product contains an RFID tag.
- The right to have embedded RFID tags removed, deactivated, or
destroyed when a product is purchased.
- The right to first class RFID alternatives: consumers should not lose
other rights (e.g. the right to return a product or to travel on a
particular road) if they decide to opt-out of RIFD or exercise an RFID
tag's "kill" feature.
- The right to know what information is stored inside their RFID tags.
If this information is incorrect, there must be a means to correct or
amend it.
- The right to know when, where and why an RFID tag is being read.
What about #3 and I-Pass? And cellphones?
Serious applications:
- Inventory management
- Store checkout
- Access control (eg of people into Lewis Tower, or of cars into a lot)
- Personnel tracking (knowing where people are)
- Computer interface to real world
- Tracking exposure to viral illness
- embedded in currency as anti-counterfeiting measure [!]
- Getting electronic devices to detect each other, and interoperate;
compare with BlueTooth
- Self-guided museum tours (where you wear the tag)
- Smart refrigerator: keeps track of expiration dates
- refrigerator + TV: you get grocery ads on TV for things currently in
your fridge.
- Smart laundry
- Where are my keys? (useful in theory, but perhaps not so practical
with passive tags)
- Where is my copy of War and Peace
- consumer recalls
- compliance monitoring for medications
- theft reduction
Technological elite: those with access to simple RFID readers? Sort of
like those with technical understanding of how networks work?
2003 boycott against Benetton over RFID-tagged clothing: see boycottbenetton.com:
"I'd rather go naked" (who, btw, do you think is maintaining their site?
This page is getting old!)
Some specific reasons for Benetton's actions:
- Their stores carry only their own brands, so they can guarantee 100%
vendor compliance
- Returns are a chronic problem in retail clothing.
- Allows rapid re-stocking of clothing taken for trying on but not
purchased
- Products are expensive enough to warrant a then-$0.25-and-more chip
Is the real issue a perception of control? See Guenther
& Spiekermann Sept 2005 CACM article, p 73 [not assigned as
reading]. The authors developed two models for control of RFID information
on tagged consumer goods:
- User-control. User implements, in effect, a password
- Agent model: you delegate access decisions to a software package that
understands your privacy preferences
Bottom line: Guenther & Spiekerman found that changing the privacy model
for RFID did not really change user
concerns.
Is there a "killer app" for RFID? Smart refrigerators don't seem to be
it.
I-Pass is maybe a candidate for active
RFID, despite privacy issues (police-related). Speedpass (wave-and-go
credit card) is another example. And cell phones do allow us to be tracked
and do function as RFID devices. But these are all "high-power" RFID, not
passive tags.
What about existing anti-theft tags? They are subject to some of the same
misuses.
Papers: Bruce
Eckfeldt: focuses on benefits RFID can bring. Airplane luggage,
security [?], casinos, museum visitors
Does RFID really matter? When would
RFID matter?
RFID uses:
tracking people within a fixed zone, eg tracking within a store:
- Gillette razor customers photographed (is RFID even necessary?)
- cosmetics customers photographed
- magazines/books
Entry/exit tracking
profiling people
cell-phone tracking: when can this be done?
Are there implicit inducements to waive privacy? If disabling the RFID
tag means having to take products to the "kill" counter and wait in line,
or losing warranty/return privileges, is that really a form of pressure to
get us to leave the tag alone?
RFID shopping carts in stores: scan your card and you get targeted ads
as you shop. From nocards.org:
"The other way it's useful is that if I have
your shopping habits and I know in a category, for instance, that you're a
loyal customer of Coca Cola, let's say, then basically, when I advertise
Coca Cola to you the discount's going to be different than if I know that
you're a ... somebody that's price sensitive." Fujitsu representative
Vernon Slack explaining how his company's "smart cart" operates.
RFID MTA hack? We'll come to this later, under "hacking". But see http://pld.cs.luc.edu/ethics/charlie_defcon.pdf
(especially pages 41, 49, and 51) and (more mundane) http://pld.cs.luc.edu/ethics/mifare-classic.pdf.
RFID and card-skimming
Card-skimming is the practice of reading information on magnetic-stripe
cards (usually ATM cards) by attaching a secondary reader over the primary
card slot. Readers can be purchased (illegally) to blend in with almost
any model of ATM. Together with a hidden camera to capture your PIN
number, these systems can be used to max out the withdrawals of dozens or
even hundreds of accounts each day.
At first sight, RFID seems like it would make this situation even worse:
your card (but not PIN) can be skimmed while
in your wallet. However, RFID can easily be coupled with "smart
card" technology: having a chip on the card that can do public-key
encryption and digital signing. (Interfacing such a chip with
magnetic-stripe readers is tricky.) With such a smart card, and
appropriate challenge-response infrastructure, skimming is useless.
Passports
See also http://getyouhome.gov
US passports have had RFID chips embedded for some years now. In the
article at http://news.cnet.com/New-RFID-travel-cards-could-pose-privacy-threat/2100-1028_3-6062574.html,
it is stated that
Homeland Security has said, in a government
procurement notice posted in September [2005?], that "read
ranges shall extend to a minimum of 25 feet" in RFID-equipped
identification cards used for border crossings. For people crossing on a
bus, the proposal says, "the solution must sense up to 55 tokens."
The notice, unearthed by an anti-RFID advocacy
group, also specifies: "The government requires that IDs be read under
circumstances that include the device being carried in a pocket, purse,
wallet, in traveler's clothes or elsewhere on the person of the
traveler....The traveler should not have to do anything to prepare the
device to be read, or to present the device for reading--i.e., passive and
automatic use."
The article also talks, though, about how passports (as opposed to the
PASS cards usable for returning from Canada or Mexico) now have
RFID-resistant "antiskimming material" in the front (and back?) cover,
making the chip difficult to read when the passport is closed.
Currently, passport covers do provide moderately effective shielding.
Furthermore, the data stream is encrypted, and cannot be read without the
possession of appropriate keys (although it may still identify the
passport bearer as a US citizen). An article in the December 2009 Communications
of the ACM by Ramos et al
suggested that the most effective attack would be to:
- eavesdrop on passport transactions at the customs counter
- decode the session later
- decrypt the session
(potentially possible, though this is not certain)
- use the data to create a physical duplicate passport
- use the duplicate passport to obtain a duplicate social security card
for the original passport owner.
The actual information on the passport consist of your name, sex, date of
birth, place of birth, and photograph. Note that to be in the vicinity of
the customs counter, you generally have to have a paid international
airplane ticket (though eavesdropping at highway crossings might also be
possible), and forged blank passport books are also relatively expensive. In
other words, this is not an easy scam to pull off. Risks to US citizens
abroad seem pretty minimal.
Tracking: Printer tracking dots; word .doc format
SSN
see http://cpsr.org/issues/privacy/ssn-faq/
Privacy Act of 1974: govt entities can't require its use unless:
- federal law specifically
allows its use (as it does for tax info, social security, drivers
licenses)
- use was required prior to 1/1/1975 (Virginia required SSN for voter
registration under second exception; overturned in ???)
SSN and:
- phone/electric/other accounts
- health insurance
- student records [!]
There had been a trend against
using the SSN for student records; some students complained that no
federal law authorized its collection for student records and therefore state schools could not require it.
Alas, while this idea was gaining traction Congress introduced the Hope
education tax credits and now it is required
that students give their SSN to colleges. Even if they don't intend to
claim the credit.
What exactly is identity theft?
National Identity Card: What are the real issues? tracking? matching
between databases? Identity "theft"? See Baase 4e p 91 / 5e p 95
Starting on 4e page 54 / 5e p 57, there's a good section in Baase on
stolen data; see especially the table of incidents. What should be done
about this? Should we focus on:
- punishing companies that are the source of the stolen data?
- requiring data leaks be publicized immediately, allowing affected
consumers to monitor their own situation?
- providing everyone with free information on their own credit reports,
to detect misuse?
- technological fixes for making data more secure?
- making stolen data less useful for bad guys; ie making it harder to
profit with online data alone?
You have to give your SSN when applying for a marriage license, professional
license, "recreational" license, and some others. Why should this be? For
the answer, see http://www4.law.cornell.edu/uscode/42/usc_sec_42_00000666----000-.html.
This is a pretty good example of a tradeoff between privacy and some other
societal goal, with the latter winning out. What do you think about this
tradeoff?
Old-fashioned examples of government privacy issues, now kind of
quaint:
Matching: Should the government be able to do data mining on their
databases? In particular, should they be able to compare DBs for:
- taxes & welfare
- taxes & social security
- bank records & welfare?
- student aid and draft registration?
- tax & immigration
Should the following kinds of data be available to the government for
large-scale matching?
- criminal databases; problem of how corrections are made
- library records - threatened by Patriot I
- records of incoming and outgoing phone calls
- PATRIOT act: bank records, ISP logs are all things gov't can now
demand without a warrant
- What are our "effects"???
Government data collection: what does this
really have to do with computing? The government has resources to keep
records on "suspects" even with pencil and paper.
Government and e-privacy:
- matching between government databases
- eavesdropping on internet communications
- eavesdropping on the phone (including VOIP)
- obtaining commercial records (bank, credit, grocery)
- getting search-engine records (google)
- transponders: I-Pass, cellphone, RFID
- facial recognition
- databases of suspicions (Terrorist Information Agency)
Most arguments today against facial recognition are based on the idea
that there are too many false positives. What if that stopped being the
case?
What about camera evidence of running lights or speeding?
Commercial privacy:
E-bay privacy - Ebay has (or used to have) a policy of automatically
opening up their records on any buyer/seller to any police department,
without subpoena or warrant.
This one is quite remarkable. What do you think? Is this ethical?
Medical Privacy - the elephant in the room?
- employment
- insurance availability
- social (ED, SSRI, therapy, any serious illness)
HIPAA (Health Insurance Portability & Accountability Act) has had a
decidedly privacy-positive effect here.
However, HIPAA does not apply at all to website data collection. Timothy
Libert wrote a paper Privacy Implications of Health Information
Seeking on the Web in the March 2015 Communications of the ACM.
This is summarized by Merchant, Looking
Up Symptoms Online? These Companies Are Tracking You.
It turns out that the vast majority of medical-information websites ()
pass your search query on to third parties.
When an html page is downloaded, it will ask your browser to grab
additional page components from other sites, eg for images, advertising or
other embedded content. When your browser requests this additional
content, its GET request usually contains "referer" [sic] information that
identifies the page you originally requested. It is these referer requests
that leak information about your search to companies who may want to
harvest the information.
On
the CDC's HIV page, third-party requests are made to the servers of
Facebook, Pinterest, Twitter, and Google. In the case of the first three
companies, the requested elements are all social media buttons, which
allow for the sharing of content via the "Recommend," "Tweet," or "Pin It"
icons .... It is unlikely that many users would understand the presence of
these buttons indicates that their data is sent to these companies. In
contrast, the Google elements on the page are entirely invisible and there
is no Google logo present.
The Google request is for the google-analytics javascript package. The
referer field for all the requests likely contains "cdc.gov/hiv",
informing all four sites that you might have AIDS. All four sites may now
send cookies, and/or engage in browser fingerprinting.
Advertisers have a well-understood interest in knowing who has HIV, or
herpes, or acid reflux or allergies (there is a lot of money in treating
long-term conditions). The Libert paper, however, discovered that two data
brokers -- Experian and Acxiom -- were also present on a small but
substantial number of pages (about 5%). These companies often resell data,
often to insurers and prospective employers and often after identifying
the name of the user involved. That is concerning.
Price Discrimination
Andrew Odlyzko's 2003 survey paper on price discrimination is at http://pld.cs.luc.edu/ethics/odlyzko.pdf.
What is the real goal behind the collection of all this commercial
information? Especially grocery-store discount/club/surveillance cards.
There are many possible goals, but here's one that you might not have
thought about, in which your privacy can be "violated" even if you are
anonymous!
To create a basic supply/demand graph, one draws curves with price on the
horizontal axis, and quantity on the vertical. The supply curve is
increasing; the higher the price the greater the supply. The demand curve,
on the other hand, decreases with increasing price. However, these are for
aggregates.
Now suppose you set price P, and user X has threshold Px.
The demand curve decreases as you raise P because fewer X's are willing to
buy. Specifically:
- P <= Px: user X buys it
- P > Px: user X does not buy it
But what you really want is to charge user X the price Px.
Example: Alice & Bob each want a report. Alice will pay $1100, Bob
will pay $600. You will only do it for $1500. If you charge Alice $1000
and Bob $500, both think they are getting a deal.
But is this FAIR to Alice?
In one sense, absolutely yes.
But what would Alice say when she finds out Bob paid half, for the same
thing?
Possible ways to improve the perception of value:
- give it to Alice earlier give her bonus tracks, too
- delete some features from Bob's copy, or disable them
What do computers have to do with this?
Airline pricing: horrendously complicated, to try to maximize revenue
for each seat.
Online stores certainly could
present different pricing models to different consumers. Does this happen?
I have never seen any evidence of it, beyond recognizing different broad
classes of consumers. Perhaps it takes the form of discounts for favorite
customers, but that's a limited form of price discrimination.
Dell: different prices to business versus education This is
the same thing, though the education discount is not nearly as steep now.
Academic journal subscriptions and price discrimination: Libraries pay
as much as 10 times for some journals as individuals!
Two roundtrip tickets including weekends can be less than one (this
example is from 2005, but the pattern is still with us; all
flights are round-trips)
origin
|
destination
|
outbound
|
return
|
cost
|
Minneapolis
|
Newark
|
Wed
|
Fri
|
$772.50
|
Minneapolis
|
Newark
|
Wed
|
next week
|
$226.50
|
Newark
|
Minneapolis
|
Fri
|
next week
|
$246.50 |
If you buy the second and third tickets and throw out the returns, you
save almost $300! Airlines have actually claimed that if you don't fly
your return leg, they can charge you extra.
The issue is not at all specific to online shopping; it applies to
normal stores as well. Sometimes it goes by the name "versioning": selling
slightly different versions to different market segments, some at premium
prices.
Online shopping
At one time, online retailers pretty much offered up the same price to
everyone, partly on the assumption that different prices for different
people would be quickly noticed.
Those were the days.
Here are some common strategies today (2015):
- Prices delivered to mobile devices may be higher than prices delivered
to regular computers
- The order in which items are listed may vary; Alice's first
page may contain more higher-priced items than Bob's
- Examples exist where Mac users were offered higher prices than Windows
users
- Item costs sometimes depend on your location (not just shipping
costs!)
- For some travel sites, registered users received lower prices than
non-registered users
None of these examples are exactly of the form "we know from his past
shopping behavior the most Peter is willing to pay; let's charge him
that". But price discrimination in online retailing is clearly increasing.
Travel sites seem to be particularly prone to this, partly because travel
prices are so wildly variable.
Grocery Store Surveillance Cards
In the industry these are called "loyalty" cards. Jewel recently dropped
theirs.
The organization CASPIAN (http://nocards.org) is against
surveillance cards. A big part of Caspian's argument appears to be that
the cards don't really save you money; that is, the stores immediately
raise prices.
customer-specific pricing: http://nocards.org/overview
One recent customer-specific-pricing strategy: scan your card at a kiosk
to get special discounts.
Jewel's "avenu" program was an attempt to create customer-specific pricing.
Customers could check in at a kiosk (either in-store or online) and get
coupons based on their shopping history. Apparently it was not a success;
Jewel later discontinued the entire card program.
Store loyalty is only one goal of surveillance cards. Another goal
within the industry is to offer the deepest discounts to those who are
less likely to try the product anyway. In many cases, this means offering
discounts to shoppers who are known to be price-sensitive,
and not to others.
Clearly, the cards let stores know who is brand-sensitive and who is
price-sensitive, although stores now have other ways to figure this out.
Loyal Skippy peanut butter
customers would be unlikely to get Skippy discounts, unless as part of a
rewards strategy. They would be more likely to qualify for Jif
discounts.
Classic price discrimination means charging MORE to your regular
customers, to whom your product is WORTH more, and giving the coupons to
those who are more price-sensitive. Well, maybe the price-sensitive
shoppers would get coupons for rice, beans, and peanut butter, while the
price-insensitive shoppers would get coupons to imported chocolates, fine
wines, and other high-margin items.
Shopper-surveillance cards probably have been used effectively for the
following two strategies:
1. To allow price discrimination: giving coupons etc to the
price-sensitive only. There may be other ways to use this; cf Avenu at
Jewel
The idea used to be that you, the consumer,
could shop around, compare goods and prices, and make a smart choice. But
now the reverse is also true: The vendor looks at its consumer base,
gathers information, and decides whether you are worth pleasing, or
whether it can profit from your loyalty and habits. -- Joseph Turow, Univ
of Pennsylvania
2. segmentation (nocards.com/overview) What about arranging the store to
cater to the products purchased by the top 30% of customers (in terms of
profitability)? In a Caspian case study, the candy aisle was reduced,
although it's a good seller, because top 30% preferred baby products. Is
this really enough to make the cards worth it to the stores, though?
Using a card anonymously doesn't help you here, as long as you keep
using the same card!
Using checkout data alone isn't enough, if "the groceries" are bought
once a week but high-margin items are bought on smaller trips.
One of the most significant examples of price discrimination is college
tuition. The real tuition equals the list price minus your school
scholarship. While many scholarships are outside of the control of the
school, the reality is that schools charge wealthier families more for the
same education.
Another example of price discrimination is student versions of popular
software (eg MSDNAA $0 pricing, or Photoshop student versions). Why do
software companies do this?
ePrivacy wrap-up
Maybe the main point is simply that no one does really care about privacy,
at least in the sense of all that data out there about us. One can argue
that at least we're consistent: collectively we tend to ignore "rights"
issues with software both when it works in our favor (file sharing) and
against us (privacy).
One secondary issue with privacy is the difference between "experts" and
ordinary people: experts know a lot
more about how to find out information on the Internet than everyone else.
We'll come back to this "digital divide" issue later, under the topic
"hacking", but note that there may be lots of available information out
there about you that you simply are not aware of.