Comp 353/453: Database Programming, Corboy
523, 7:00 Thursdays
Week 9, Mar 22
Read in Elmasri & Navathe (EN)
- Chapter 15, Normalization
I redid the week-7 notes on INVOICE.
Second look at PHP PDO and LAMP (or WAMP)
PHP basics
The main purpose of PHP is actually to create and process forms, using
server-side scripting. Databases are just central examples of this.
Today's demo is on my laptop: I have apache and php installed. I have php files in /var/www; when I access these through the browser they execute.
The first example is info.php:
This produces quite a lot of output; note in particuar the magic_quotes_gpc value.
Here is the greeting demo from E&N (greeting.php):
<?php
// greeting demo from Elmasri & Navathe 14.1
// this prints a welcome message if the user enters their name
if ($_POST['user_name']) {
print("Welcome, ");
print($_POST['user_name']);
} else {
// create the form
$action=$_SERVER['PHP_SELF'];
print <<<_HTML_
<FORM method="post" action="$action">
Enter your name: <input type="text" name="user_name">
<BR>
<INPUT type="submit" value="Submit name">
</FORM>
_HTML_;
}
?>
The associative-array variable $_POST contains data sent as the result
of an HTML POST method. The value for key "submit" (the name of the
submit button) would definitely be set. In this case, we print the
username, $_POST['user_name'].
Before the submit button is clicked the $_POST structure is empty, and so we initially execute the else
part above. $action is set to the name of the current script, which is
also the name of the script to process our input. Everything between
the print <_HTML_ and the following _HTML_
(which must begin in column 1!!)
is treated as static text (a so-called
"heredoc"), and is printed "as is", except that anything beginning
with $ is treated as a PHP variable and its value is printed instead.
The only variable is $action (which in many cases will be "", meaning
to use the same source file). We could also have used ordinary print
statements here, but those are tedious.
My version is slightly different from the book's version, which had
<FORM method="post" action="$_SERVER['PHP_SELF']">
The part in bold here is a "superglobal" variable, and my installation
of php does not allow superglobals in "here docs". I can only assume
this is a security issue; note the workaround above.
It can be confusing to figure out at what point we "start over", and
forget the existing $_POST. Doing a browser reload resends the POST
data and so we stay on the second page; going to the location bar and
hitting return reloads without reposting and so we go back to the first page.
Note we simply ignore <html><body>, etc. I really
should put these in. Note also that printing output works as desired,
except your output is formatted according to where it is in the html.
Next is selection.php, which replaces the input box for a name with a selection for department:
<FORM method="post" action="$action">
Select your department:
<select name="department">
<option value="administration">Administration</option>
<option value="headquarters">Headquarters</option>
<option value="research" selected="selected">Research</option>
</select>
<BR>
<INPUT type="submit" value="Submit">
</FORM>
http://localhost/selection.phpBefore going further, let's introduce some syntax errors into the php file, and see what happens.
As our final forms-only example, here is emp.php, which creates a form with multiple fields, and two buttons. Here is the form-creation part (as a here doc):
print <<<FORMEND
Enter new employee:<p>
<form method="post" action="">
<input type="text" name="fname" value="ralph">
<input type="text" name="minit" size="1" value="j">
<input type="text" name="lname" value="wiggums"> required
<p>
<input type="text" name="ssn" value="abcdefghi"> required
<br><input type="text" name="sex" value="M"> M/F
<br><input type="text" name="bdate" value="1980-07-04"> YYYY-MM-DD
<br><input type="text" name="salary" value="9999"> (annual salary)
<br><input type="text" name="super_ssn" value="999887777"> supervisor (by SSN)
<br><input type="text" name="address" value="no fixed abode"> address
<br><input type="text" name="dno" value="4"> department number
<p><input type="submit" name="submit" value="submit data">
<p><input type="submit" name="update" value="update">
</form>
FORMEND;
Default values have been provided. When the user clicks "submit", we
simply print this. Note the button "update", not used here. Both
buttons are of type "submit", but only the first is named "submit", meaning that only the first will trigger the if ($_POST['submit']).
Last week we looked briefly at the problem of SQL injection:
allowing unchecked user-supplied strings to be used as SQL fields in
dynamically executed strings. Prepared statements pretty much make this
impossible. There is, however, also the concern about HTML injection, more commonly known as cross-site scripting or XSS.
We should be more careful about echoing back our HTML. When we're the
only viewer, all we can do is feed ourselves our own script, but if we
post something on a social networking site like this:
I agree! <script>do_bad_things()</script>
http://localhost/selection.php
then we've, well, done bad things. In this class we are not going to obsess about sanitizing our HTML (though we really should). We will, however, try to use htmlspecialchars().
empquery.php
The file empquery.php makes a single query. There is no form involved;
there is no provision for changing the arguments of the query except to
edit the file.
Now let's look at eform1.php and eform2.php,
above. eform1.php creates a form just like emp.php, but its action is
"eform2.php". The latter actually adds the user to our database, and
then retrieves the entire (newly updated) employee table and prints
that. The main difference between this pair of forms and employees.php
is that the latter handles both roles (entry form and doing the
insertion / displaying the updates as a single php file. In fact, the
main purpose of eform1 and eform2 is to separate the initial-display
and POST processing, hopefully for clarity.
empupdate.php is a version of eform1/eform2 that merges the two forms
into a single file, but still retains the form1/form2 flow. The final
step, done in employees.php,is to merge everything into a single logical page.
Java Programming
JDBC and SQLJ are two popular Java interfaces to SQL. Note that SQLJ
requires that your sql statements be compiled into your program; this
is a major problem. JDBC allows dynamically created strings to be used
for queries. Still, the strings are interpreted, leaving room for problems. The worst such problem is "SQL Injection".
Documentation is found in under "java.sql".
Note that JDBC would only be applicable if you were building your
application with java. Perhaps most web interfaces are browser-based.
I need to make sure that my CLASSPATH contains mysql_jdbc.jar.
We'll look at two examples. The first is employees1.java,
which shows the process of creating a Connection object. This object
knows that we are creating a connection to MySQL (some of the
commented-out parts relate to Oracle). The book's way of creating a
connection is slightly different, using
Class.forName("oracle.jdbc.driver.OracleDriver");
The two amount to the same thing.
The next thing done in employees1 is to create a Statement from the
connection, and then execute the query. The query returns a ResultSet.
Note the getString() method to extract data, and the next() method.
The second program is employees2.java. Here, I use a parameterized query (prepared statement).
Why not build strings manually? See employees3.java.
A problem occurs if there are quotes in the data, particularly if that
data is user-supplied. Suppose the user provides a USERNAME and a
PASSWORD string, and the query does
select * from AUTH_USERS where user=$USERNAME
Suppose the user sends USERNAME= ' or '1'='1
Then the above may be naively formatted into
select * from AUTH_USERS where user='' or '1'='1' (note two extra quotes!)
This is now everyone.
Prepared Statements
Above we looked at Java's PreparedStatement objects:
PreparedStatement p = connection.prepareStatement(
"select
e.fname, e.lname, e.ssn, e.bdate, e.salary, d.dname from employee e,
department d "
+ "where e.dno=d.dnumber and e.dno=? and e.lname=?"
);
Prepared statements, or parameterized statements/queries, can be either client-side or server-side.
Client-side means that the client replaced the prepared-statement '?'
placeholders with appropriately escaped strings, and then passed the
entire query to the database. The client must be sure to handle the
escaping of embedded quotes correctly or risk a SQL injection attack.
Server-side prepared statements mean that the query with embedded '?'s
is sent to the database server, and then later the values to be plugged
in are sent. Ideally, the value strings are sent as an array of raw
string objects, so there is no ambiguity as to how escaping of
quotation marks is to work.
To see some of this in action, turn on the general_log_file in the
MySQL configuration file (/etc/mysql/my.cnf for me), and enable query
logging
general_log_file = /var/log/mysql/mysql.log
general_log = 1
After doing this, let's run employee2.java again, with e.lname of "O'Hara". We get (or got; this is actually from 2011) something like
52 Query SHOW COLLATION
52 Query SET NAMES latin1
52 Query SET character_set_results = NULL
52 Query SET autocommit=1
52 Query SET sql_mode='STRICT_TRANS_TABLES'
52 Query select e.fname, e.lname, e.ssn, e.bdate,
e.salary, d.dname from employee e, department d where e.dno=d.dnumber
and e.dno=5 and e.lname='O\'Hara'
Note that the escaped value for e.lname does show up here, 'O\'Hara',
but that was done by the client, that is, by the JDBC connection. The
last line above is also what appears when we print the
preparedStatement object p after the final p.setString(), suggesting
that at this point (before query execution) java has already replaced
the '?' with its corresponding argument.
By comparison, here's the same sort of thing after using PHP preparedStatements, which use server-side prepares (I've omitted a few unnecessary items)
56 Query PREPARE
MDB2_STATEMENT 'select e.fname, e.lname, e.ssn, e.bdate, e.salary,
d.dname from employee e, department d where e.dno=d.dnumber and e.dno=?
and e.lname=?'
56 Query SET @0 = 5
56 Query SET @1 = 'O\'Hara'
56 Query EXECUTE MDB2_STATEMENT USING @0, @1
This time it is the server doing the escaping where 'O\'Hara' is displayed.
The PHP code for the above used the PEAR MDB2 library:
$query = "select e.fname, e.lname,
e.ssn, e.bdate, e.salary, d.dname from employee e, department d where
e.dno=d.dnumber and e.dno=? and e.lname=?";
$types = array('integer', 'text'); // provide argument types
$qstmt = $db->prepare($query, $types, MDB2_PREPARE_RESULT);
$queryargs = array(5, "O'Hara");
$qres = $qstmt->execute($queryargs);
If instead of $qstmt->execute($queryargs) we split it up as
$qstmt->bindValueArray($argArray);
print_r($qstmt);
$qstmt->execute();
we see that, after binding but before execution, the '?' placeholders have not been expanded. That won't happen until everything reaches the server side.
When prepared statements are used, it helps if something is known about
the types involved. For example, when replacing a '?' with
ssn=888776666, this is a string and so should be quoted. However, when
replacing ? with dno=5, this is an integer and so should not be quoted.
Also, unspecified values at the application side need to be replaced
with NULLs somewhere.
Server-side preparation can infer the type of any column value from the
appropriate table definition. Client-side preparation must do a little
more work.
Design Guidelines and Normalization
Normalization refers to a mathematical process for decomposing tables
into component tables; it is part of a broader area of database design.
The criteria that guide this are functional dependencies, which should really be seen as user-supplied constraints on the data.
Our first design point will be to make sure that relation and entity
attributes have clear semantics. That is, we can easily explain
attributes, and they are all related. E&N spells this out as
follows:
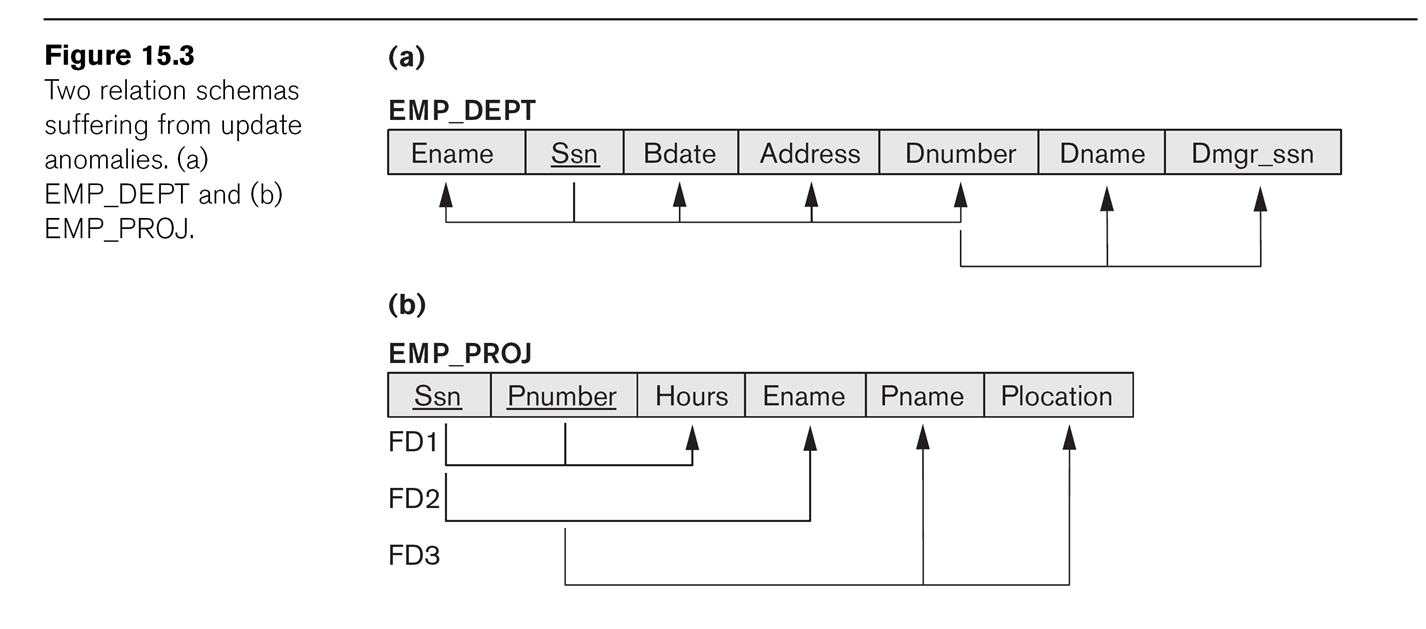
E&N Guideline 1: Design a relation
schema so that it is easy to explain its meaning. Do not combine
attributes from multiple entity types and relationship types into a
single relation.
As examples, consider
EMP_DEPT
Ename
Ssn
Bdate
Address
Dnumber
Dname
Dmgr_ssn
This mixes employee information with department information.
Another example is
EMP_PROJ
Ssn
Pnumber
Hours
Ename
Pname
Plocation
Both these later records can lead to
- insertion anomalies: when adding an employee, we must assign them
to a department or else use NULLs. When adding a new department with no
employees, we have to use NULLs for the employee Ssn, which is supposed
to be the primary key!
- deletion anomalies: if we delete the last EMP_DEP record from a department, we have lost the department!
- update anomalies: what if we update some EMP_DEPs with the new Dmgr_ssn, but not others?
This leads to
E&N Guideline 2: design your
database so there are no insertion, deletion, or update anomalies. If
this is not possible, document any anomalies clearly so that the update
software can take them into account.
The third guideline is about reducing NULLs, at least for frequently
used data. Consider the example of a disjoint set of inherited entity
types, implemented as a single fat entity table. Secretaries,
Engineers, and Managers each have their own attributes; every record
has NULLs for two out of these three.
E&N Guideline 3: NULLs should be
used only for exceptional conditions. If there are many NULLs in a
column, consider a separate table.
The fourth guideline is about joins that give back spurious tuples. Consider
EMP_LOCS
Ename
Plocation
EMP_PROJ1
Ssn
Pnumber
Hours
Pname
Plocation
If we join these two tables on field Plocation, we do not get what we want! (We would if we made EMP_LOCS have Ssn instead of Ename, and then joined the two on the Ssn column.) We can
create each of these as a view:
create view emp_locs as select e.lname, p.plocation from employee e, works_on w, project p
where e.ssn=w.essn and w.pno=p.pnumber;
create view emp_proj1 as select e.ssn, p.pnumber, w.hours, p.pname, p.plocation
from employee e, works_on w, project p where e.ssn=w.essn and w.pno = p.pnumber;
Now let us join these on plocation:
select * from emp_locs el, emp_proj1 ep where el.plocation = ep.plocation;
Oops. What is wrong?
E&N Guideline 4: Design relational
schemas so that they can be joined with equality conditions on
attributes that are appropriatedly related ⟨primary key, foreign key⟩
pairs in a way that guarantees that no spurious tuples are generated.
Avoid relations that contain matching attributes that are not ⟨foreign
key, primary key⟩ combinations.
Functional Dependencies and Normalization
A functional dependency is a kind of semantic constraint.
If X and Y are sets of attributes (column names) in a relation, a
functional dependency X⟶Y means that if two records have equal values
for X attributes, then they also have equal values for Y.
For example, if X is a set including the key attributes, then X⟶{all attributes}.
Like key constraints, FD constraints are not based on specific sets of
records. For example, in the US, we have {zipcode}⟶{city}, but we no
longer have {zipcode}⟶{areacode}.
In the earlier EMP_PROJ, we have FDs
Ssn ⟶ Ename
Pnumber ⟶ Pname, Plocation
{Ssn, Pnumber} ⟶ Hours
In EMP_DEPT we have FDs
Ssn ⟶ Ename, Bdate, Address, Dnumber
Dnumber ⟶ Dname, Dmgr_ssn
Sometimes FDs are a problem, and we might think that just discreetly
removing them would be the best solution. But they often represent
important business rules; we can't really do that either.
A superkey (or key superset) of a relation schema is a set of attributes S so that no two tuples of the relationship can have the same values on S. A key is thus a minimal superkey:
it is a superkey with no extraneous attributes that can be removed. For
example, {Ssn, Dno} is a superkey for EMPLOYEE, but Dno doesn't matter
(and in fact contains little information); the key is {Ssn}.
Note that, as with FDs, superkeys are related to the sematics of the relationships, not to particular data in the tables.
Relations can have multiple keys, in which case each is called a candidate key.
For example, in table DEPARTMENT, both {dnumber} and {dname} are
candidate keys. For arbitrary performance-related reasons we designated
one of these the primary key; other candidate keys are known as secondary keys.
A prime attribute is an attribute (ie column name) that belongs to some candidate key. A nonprime attribute is not part of any key.
A dependency X⟶A is full if the dependency fails for every proper subset X' of X; the dependency is partial if not, ie if there is a proper subset X' of X such that X'⟶A.