Transactions and Locking
Read in Elmasri & Navathe (EN)
- Chapter 21: transactions
- Chapter 22: Concurrency Control
Abstract Transactions
ACID
Schedules
Serializability
General Isolation Levels
Postgres and MVCC
Postgres Isolation Levels
Snapshots
Repeatable Read
Serializable
Locking
2-phase locking
deadlock
A transaction is a set of operations, which we can
idealize as read(X), write(X), which at the end we either commit
(save) or rollback/abort (discard).
Generally we hope rollbacks are rare.
In Postgres or MySQL, a transaction begins with start transaction;
as follows
start transaction;
-- or begin;
insert into employee values ('Ralph', 'I', 'Wiggum', '123212321', null,
null, 'M', 23000, '888665555', 1);
Let's call this transaction T1. At this point if we view the employees from
within T1, with the following, we will see Ralph:
select fname, lname from employee;
But if we open another DB window, Ralph won't be there. That same
query run in another window amounts to a separate one-line transaction. That
makes sense; to allow otherwise would be to allow the second transaction to
read T1's "uncommitted" data, which, as we shall see, is a bad idea.
Ralph will appear to other readers once the inserting transaction T1 ends
with
commit;
Alternatively, we can end with "rollback;" (or "abort;").
What happens if, while our Invisible Ralph (that's what the minit='I' is
for) transaction is pending, we try in another transaction T2 to insert
someone else?
insert into employee values ('Clarence',
'c', 'Wiggum', '123212321', null, null, 'M', 33000, '888665555', 1);
Postgres is in a bind here: we cannot insert both Ralph and
Clarence. So, what it does is quite simple: T2 is suspended
until T1 commits or aborts. If it aborts, Clarence gets inserted. If T1
commits, however, T2 gets a duplicate-key error: there already is
an employee with SSN 123212321 (that is, Ralph).
Suppose, while Ralph's transaction is pending, we try instead to insert
Clarence with a different SSN:
insert into employee values ('Clarence',
'c', 'Wiggum', '321232123', null, null, 'M', 33000, '888665555', 1);
This time there is no problem. Postgres is "freezing" just the pending new record
with ssn '123212321', not the entire employee table.
Postgres is doing this without locks, however. We will
return to this below.
On a per-session basis, one can also disable autocommit:
set autocommit = 0; -- MySQL
\set autocommit off; -- Postgres
But you probably don't want to.
Abstract transactions
We will assume that the operations are read(X) and write(X), for X a
field/record/block/table.
Fig 21.2 shows two example transactions.
T1: read(X), write(X), read(Y), write(Y)
T2: read(X), write(X)
Ideally, we execute the transactions one at a time, with no overlap. In
practice, because of the considerable I/O-wait for disk retrieval, we cannot
afford that. Transactions will overlap.
We need to figure out how to arrange for this to happen safely.
Here are two problems:
Lost-update (write/write) problem:
this occurs when one transaction writes a value that another then
overwrites. See Fig 21.3a. T1 is
transferring N dollars from X to Y, while T2 is adding M dollars to X.
T2.write(X) overwrites
T1.write(X).
T1
|
T2
|
read(X)
X = X-N
|
|
|
read(X)
X = X+M
|
write(X)
read(Y)
|
|
|
write(X)
|
Y = Y+N
write(Y)
|
|
Dirty-Read (read/write) problem:
this occurs when one transaction reads an item that another then overwrites.
This would end up as a lost-update, but consider Fig
21.3b where T1 actually aborts after write(X).
T1
|
T2
|
read(X)
X = X-N
write(X)
|
|
|
read(X)
X = X+M
write(X)
|
read(Y)
abort/rollback
|
|
Fig 21.3c shows a corrupted result; an
abort would have been an improvement!
The system log, or journal,
is a master list of all operations performed, used in the event of rollback.
Failures leading to rollback may be system crash, lack of disk space, lookup
error (eg SQL error), locking problems, or other physical or logical errors.
Items read here can be individual record attributes, entire records, or
entire tables. When joining tables, the entire table is read.
The System Log
In order to recover from transactions that encounter
problems (including full-on system crashes), databases must maintain a
system log, or journal. The log is
written to disk in such a way that it survives even if the transaction's
normal data writes are still sitting in a cache somewhere.
For each transaction, the following information is recorded in the log:
- start
- each write(), including what field or record was written and either
the value written or the old value or both
- the final commit or abort
Sometimes the results of each read() are also included, though this has
more to do with auditing than recovery.
The basic idea is that, on database restart after a crash, the first step
is to search the log for transactions that have committed or aborted. The
values written by those transactions can then be verified; for committed
transactions the new value should be present in the actual database and
for aborted ones the old value should be present. The next step is to
identify those transactions that have not committed or aborted; those
transactions will be rolled back using the write()
information.
The ACID test
ACID is an acronym enumerating the following set of features relating to
support for parallel transactions.
- Atomicity: either all
steps of a transaction are performed, or none are. We
either commit the entire thing or rollback completely.
- Consistency preservation: the
individual transaction should preserve database consistency and database
invariants
- Isolation: transactions should
appear to be executing in isolation.
- Durability: committed
transactions survive DB crashes
These properties are fundamentally about queries as a whole, whether or not
they are grouped into transactions. On the face of it, durability has little
to do with parallelism, and consistency is generally understood as an
attribute for individual queries. There are other redundancies here as well;
the main points for transactions are atomicity and isolation, with
the latter understood as a special case of correctness.
Note that Consistency is closely related to Isolation: if each transaction
preserves consistency, and the transactions appear to execute in Isolation,
then a series of transactions will be consistency-preserving, at least if
Isolation means something like Serializability. However, serializability
might be a stronger condition than necessary, if we really had a good
definition for isolation. (Which we in fact do not; think about it. Query 1
may affect the outcome of Query 2 even if they are executed one after the
other.)
The ACID acronym was introduced by Reuter and Härder in 1983, after the
basic properties had been worked out by Gray in the late 1970's. Consistency
and Durability are not specific to transactions; they apply to any database
operations.
Transaction schedules
Transaction schedules are lists of read/write operations of each
transaction, plus commit/abort. The operations of each individual
transaction must be in their original order.
Eventually we will enforce
schedules by using locking, but for
now we just consider schedules abstractly, with an eye to how easy it will
be to recover from a problem.
Here are two examples representing the tabular schedules above illustrating
the lost-update and dirty-read problems:
Sa: Fig 21.3a:
r1(X), r2(X), w1(X), r1(Y), w2(X), w1(Y), c1, c2
Sb: Fig 21.3b:
r1(X), w1(X), r2(X), w2(X), r1(Y), a1
Conflict
Two operations is a schedule conflict
(where the word is to be taken as indicating potential
conflict) if:
- They belong to different transactions
- They access the same data item (eg X)
- At least one of the operations is a write()
For example, in Sa, r1(X) and w2(X) conflict. So do r2(X) and w1(X). What
does not conflict? r1(X) and r2(X), r1(X) and w1(X).
Conflicting operations are those where interchanging the order can result in
a different outcome. A conflict is read-write
if it involves a read(X) in one transaction and write(X) in the other, and write-write if it involves two
transactions each doing write(X).
A complete schedule is a total
order of all the operations, including abort/commits. (E&N allows some
partial ordering of irrelevant parts).
Given a schedule S, the committed
projection C(S) is the subset of S consisting of operations (r1(X),
w2(Y), etc) that are part of transactions that have committed (that is,
r1(X) would be part of C(S) only if transaction 1's commit, c1, were also
part of S). This is sometimes useful in analyzing schedules when
transactions are continuously being added.
We can build a transaction precedence
graph based on schedule conflict, given a schedule S. Let us
say Ti ⟶ Tj if Ti and Tj conflict as above, and one of the following occurs:
- Ti executes write(X) and later Tj executes read(X)
- Ti executes read(X) and later Tj executes write(X)
- Ti executes write(X) and later Tj executes write(X)
These are the three specific cases of conflict that can occur; note that at
this level we distinguish between read-write and write-read.
Demo: build graphs for Fig 21.3(a), (b).
Note that the figure determines the schedule.
Recoverable and nonrecoverable schedules
Given two transactions T and T', we say T reads
from T', or T depends on
T', if T' does a write(X) and then later T does a read(X) (this is Case 1 of
T'⟶T above) Thus, the outcome of T may depend on the (at least in part)
earlier T'.
A schedule is recoverable if no
transaction T commits until all T' where T reads from T' have already
committed. Otherwise a schedule is nonrecoverable.
The point is that if T reads from T', then if T' aborts, T must abort
too. So T waits to commit until T' commits. Given a recoverable
schedule, we never have to abort a
committed transaction. This is, in practice, an essential rule.
Consider the following modification of Sa above:
S'a: r1(X), r2(X), w1(X), r1(Y), w2(X), c2, w1(Y), c1.
In tabular form this is
| T1 |
T2 |
| read(X) |
|
|
read(X) |
| write(X), read(Y) |
|
|
write(X) |
|
commit |
| write(Y) |
|
| commit |
|
This is recoverable: neither transaction reads from the
other (it would still be recoverable if T1 read from T2, because T1 commits
after T2). Note, however, there is a risk of lost
update; T2's write(X) may overwrite T1's write(X).
But now consider
Sc: r1(X), w1(X), r2(X),
r1(Y), w2(X), c2, a1
nonrecoverable:
T2 reads X from T1 but T2 commits first
Sd: r1(X), w1(X), r2(X),
r1(Y), w2(X), w1(Y), c1, c2; recoverable because T2 reads
X from T1 but T1 commits first
Suppose T1 aborts in Sd. Then we have Se, in which T2 aborts because it read
from T1 and T1 aborted:
Se: r1(X), w1(X), r2(X), r1(Y), w2(X), w1(Y), a1, a2;
Though recoverability implies no committed transaction needs to be rolled
back, we still may have cascading rollback.
A schedule is said to avoid cascading
rollback, or to be cascade-avoiding, if every transaction T only
reads items that were earlier written by committed
transactions. In this case, an abort of some other transaction will not
cause T to abort. How can we achieve this in Sd/Se? By delaying r2(X)
until after c1.
There is also a notion of strict
schedule, in which transactions do not use X for either read or write until
all transactions that wrote X have committed. This is more expensive to
require, but makes recovery not only theoretically possible, but practical.
strict implies cascade-avoiding implies recoverable, but not the reverse.
Consider the following three transactions:
T1: X+=10, Y*=1.1;
T2: Y+=10, Z *= 1.1;
T3: Z+=10, X *= 1.1;
What happens if we do these in order T1, T2, T3? If X, Y and Z are initially
100 (so adding 10 is the same as multiplying by 1.1), then in the order
above we finish with X=121 (multiplication was second), Y=120
(multiplication was first) and Z=120 (again, multiplication was first).
We get similar end results in any
serialized order: one of the values will be 121, and the other two will be
120.
What happens if we create a schedule in which we do all the additions
and then all the multiplications? Note that, if we defer the commits, this
can be a recoverable schedule. And there are no lost
updates. But it is still not equivalent to any serial
schedule: we end up with X=Y=Z=121.
To run this in Postgres:
create table xyz(x integer, y integer, z
integer);
insert into xyz values (100, 100, 100);
T1: begin;
update xyz set x = x+10;
update xyz set y = y*1.1;
T2: begin;
update xyz set y = y+10;
update xyz set z = z*1.1;
T3: begin;
update xyz set z = z+10;
update xyz set x = x*1.1;
One would probably also set an isolation level, with
set transaction isolation level repeatable
read;
Serializability
The best definition of transaction Isolation is that the transactions are
executed serially. Unfortunately, that is too inefficient.
Instead, we look for schedules that are in some sense equivalent
to a serial schedule. In Fig 21.5, (a) and
(b) show two serial schedules. Schedule (c) has a lost update (T1's write(X)
is clobbered by T2's later write(X)); schedule (d) is ok (in a sense to be
defined below) because we can move T2 to the end of T1.
A schedule is serializable if it is
equivalent to a serial schedule. For equivalence, we can use result
equivalence, but that is intractable. Instead we use conflict
equivalence. Two schedules are conflict-equivalent
if the order of any two conflicting
operations is the same in both schedules. We can reorder the other
(nonconflicting) parts to get the serialization we need.
Conflict-serializability algorithm
The first step is to build the transaction precedence (directed) graph
above, in which we have an arc Ti⟶Tj if any of these
three cases of schedule conflicts holds:
- Ti executes write(X) and later Tj executes
read(X)
- Ti executes read(X) and later Tj
executes write(X)
- Ti executes write(X) and later Tj executes
write(X)
If the graph has no cycles, it is conflict-serializable.
To look for cycles, we do a topological sort (ie find a total order of the
nodes consistent with the Ti⟶Tj ordering; see below).
The original schedule is conflict-equivalent to the schedule of executing
the transactions in that order.
The actual topological-sort algorithm is as follows: first, find all Ti that
do not have any predecessors, ie Tk with Tk⟶Ti.
Do these first, and remove all Ti⟶Tj links. Now
repeat, until there are no more nodes. If at some stage there are no Ti
without predecessors, then there must be a cycle.
Fig 21.7 shows the graphs for the schedules
in Fig 21.5.
Running the conflict-serializability algorithm is often impractical. Another
approach is to identify protocols that transactions can
follow that are sufficient to ensure serializability.
View Serializability
A less restrictive schedule-equivalence rule is that of view equivalence.
This essentially means that for each read operation on a specific variable
X that appears in both of the two schedules, the same value is returned
for each read. Specifically, if S and S' are the two schedules in
question, and if ri(X) appears in transaction Ti in
schedule S, and the same ri(X) appears in S', then both will
read the value written by wj(X) in earlier transaction Tj.
(We also need a rule to require that S and S' have the same set of final
writes.)
View serializability is similar to conflict serializability if there are
no blind writes, that is, transactions that write a
value without reading it. No blind writes means that if Ti has
a write wi(X), then it has an earlier ri(X). There
is also a rule that the value X written depends only on the value of X
read, which is less convincing as, for example, we may be swapping X and
Y.
Debit-credit transactions
These are transactions built from pieces of the form read(X), X+=N,
write(X). We do not have to serialize these! As long as we avoid the
lost-update problem, we can interleave increments and decrements from
different transactions without harm, because addition is commutative. The
schedule below is not conflict-serializable, but it yields the same result,
namely X = X+N−M, Y=Y+M−N.
T1
|
T2
|
read(X)
X+=N
write(X)
|
|
|
read(Y)
Y+=M
write(Y)
|
read(Y)
Y−=N
write(Y)
|
|
|
read(X)
X−=M
write(X)
|
Isolation Rules
SQL supports these isolation rules:
- read uncommitted
- read committed
- repeatable read
- serializable
In tabular form, these allow:
| isolation level |
dirty read |
nonrepeatable read |
phantom read |
| read uncommitted |
yes |
yes |
yes |
| read committed |
no |
yes |
yes |
| repeatable read |
no |
no |
yes |
| serializable |
no |
no |
no |
A dirty read is a read by one transaction of data
written by another transaction that has not yet committed. For example: T1
reads a value written by T2; T2 later aborts. This
could also be described as an uncommitted read.
An example of a nonrepeatable read: T1 reads
a value, and later reads the value again. In between, T2 (which
may have started earlier, but has since committed) updated the value.
A phantom read occurs when the second transaction
inserts an entirely new row. For example, suppose T1 reads a
set of rows determined by a (possibly empty) WHERE clause. T2
now adds a new row that meets the WHERE condition. If T1
repeats the read of the rows, it gets a different set of rows.
Here is an example:
T1:
select sum(salary) from employee where dno = 2;
T2:
insert into employee (fname, lname, ssn, dno, salary) values ('Robert',
'Smith', '991004321', 2, 35000);
T1:
select sum(salary) from employee where dno = 2;
The second time T1 executes the query, it gets a different value.
However, no individual records were changed.
Sometimes a nonrepeatable read is described as one transaction reading
from a write by another transaction, while a phantom
read is described as one transaction reading from an append
by another. That is, an update to a record represents a
write, while the insertion of a new record represents an
append.
The serializable category does not mean the
transactions are actually conflict-serializable; it only means that none
of the three read() anomalies are permitted. The serializable category
prohibits not only phantom reads, but also any serialization
anomaly: any end result that isn't the same as the result of
executing the transactions in at least one serialized order.
Postgres and MVCC
To enforce isolation levels, Postgres implements Multi-Version
Concurrency Control, or MVCC. When you update a record in Postgres, the
old version isn't overwritten. Instead, it lingers, coexisting with the
new version of the record. Record versions are often called tuples
in Postgres; the rule is that any individual tuple is immutable;
that is, is never changed. There is no such thing as an in-place field
update!
Every transaction has a numeric transaction id,
available with select
txid_current(). Every tuple has special fields xmin
and xmax. When a tuple is
inserted (or updated), xmin
is set to the transaction id of the inserting transaction; that is, each
tuple carries an identification of the transaction that created it.
Similarly, the xmax value is
set when a tuple is marked as deleted. The tuple is not physically
deleted, though, at least not right away, but Postgres will not show the
deleted tuple to any transaction with transaction id > xmax. An older
(but long-running) transaction, however, might be shown this now-deleted
tuple (if the isolation level were repeatable-read or above).
The Postgres system also maintains a list of transactions that are
currently pending, so the commit status can easily be determined.
When Postgres finds a record, perhaps through the index, it actually
finds a linked list of tuples, starting with the most recent. We can call
this the tuple chain. For a given transaction, Postgres
searches the list for a tuple that has either committed or else
was created by that particular transaction. Higher isolation
levels add additional constraints, but the rule stated here is sufficient
to enforce the Read Committed isolation rule: a
transaction will simply not find tuples created by another uncommitted
transaction.
Let's see this Read Committed effect in action. We'll start a new
transaction T1 and insert Ralph Wiggum, as in the example at the
beginning:
begin; --
T1
insert into employee values ('Ralph', 'I', 'Wiggum', '123212321', null,
null, 'M', 23000, '888665555', 1);
If we run psql in a second window, effectively transaction T2, Ralph is
invisible. T1 has not committed.
Now let us have the first transaction, T1, commit. The
second window now sees Ralph.
MySQL also uses MVCC (as does Oracle), but it is implemented slightly
differently. The current record in the database is updated in place, but the
original version is saved somewhere else, in a special "recovery" area.
MySQL (unlike Postgres) uses locks for isolation levels repeatable-read and
serializable.
Postgres does suffer from so-called "bloat", as the number of tuples for the
same record increases. A tuple can be deleted when there are no active
transactions still relying on its value, but usually it is the
responsibility of the auto-vacuum process to do this.
Postgres Isolation Levels
Postgres uses MVCC (that is, the tuples with the xmin and xmax tags,
below) to implement isolation levels above Read Committed. Here's a
Postgres table:
| Isolation Level |
Dirty Read |
Nonrepeatable Read |
Phantom Read |
Serialization Anomaly |
| Read uncommitted |
Allowed, but not in PG |
Yes |
Yes |
Yes |
| Read committed |
No |
Yes |
Yes |
Yes |
| Repeatable read |
No |
No |
Allowed, but not in PG |
Yes |
| Serializable |
No |
No |
No |
No |
Postgres does not allow Read Uncommitted at all. Postgres does not allow
Phantom Reads with Repeatable-Read isolation, but does allow serialization
anomalies. Postgres does not make a distinction between nonrepeatable
reads and phantom reads.
We've already seen some of the behavior of Read Committed. Let's repeat
that, with two transactions, T1 and T2 in that order. T2 will be the
transaction that inserts Ralph. When T2 first inserts Ralph, the insertion
is not visible to T1, as it has not committed. Nor would Ralph be visible
to a third transaction, T3, that started after T2. Once T2 has
committed, Ralph is visible to both T1 and T3. For Read
Committed isolation, all that matters is whether the writing transaction
(T2 here) has committed.
Now let's see Read Committed in action with a single update.
We'll assume Ralph Wiggum has been added previously with a salary of
23000.
T1: begin;
set transaction isolation level read committed;
-- optional, as this is the default
select salary from employee where lname = 'Wiggum';
We get 23000, as expected. But T1 has not yet committed. Now we run T2;
note that T2 commits right away. (This, by the way, is the same as running
the update statement here without the begin/commit.)
T2: begin; update employee set salary = salary
+ 1000 where lname = 'Wiggum'; commit;
T1 is still running. Let's see what we read now for Ralph's salary:
T1: select salary from employee where lname =
'Wiggum';
We get 24000! That is, T1 reads T2's update.
But what if both T1 and T2 try to update
Ralph's salary? We will start T1 and then T2 as before, with Ralph added,
at a salary of 23000. T1 will update Ralph's salary:
update employee set salary = salary+1000 where
lname='Wiggum';
Now let's have T2 do a different update:
update employee set salary = salary+2000 where
lname='Wiggum';
This update simply hangs until T1 aborts or commits.
This is because of what we might call the conflicting-write
rule: a transaction may not insert or update a record if another
uncommitted transaction has already done so. In light of this rule, there
is no way for T2 to carry out this update! If T1 aborts, T2's update will
change Ralph's salary to 25000; if T1 commits, T2's update will change
Ralph's salary to 26000. T2 cannot update Wiggum's salary
until T1 commits (or aborts). The conflicting-write rule means that T2
cannot update a value (Wiggum's salary) that is currently "in play"; that
is, subject to an update by an uncommitted transaction.
Finally, let's have T2 insert into a table. First we create the table,
and populate it with values 1 and 2:
create table numbers (num integer primary
key);
insert into numbers values (1),(2);
We start two transactions, and then have T2 enter a value:
insert into numbers values(3);
This is visible in T1 after T2 commits, but not before. This is a phantom
read. It behaves no differently than an update (that is, than a
nonrepeatable read).
To implement read-committed, to a first approximation
all Postgres has to do is the following:
- make sure that transactions don't read tuples
created by as-yet-uncommitted transactions. Usually a read will find an
earlier tuple on the "tuple chain", and read from that instead.
- make sure transactions don't write to records (don't
create new tuples) where there exists a tuple in the tuple chain that is
currently marked as having been modified by another, still-uncommitted
transaction. Writing to a different tuple is not allowed; the
transaction must hang until the first transaction finishes.
As tuples are marked with their transaction ids, and as Postgres can easily
tell if a transaction id has committed, this is straightforward.
This is not quite the full story, however. All the individual queries
(select/update/insert) we have been running are executed serially; that is,
we run one query at a time. Transactions can overlap, because
transactions last until we choose to enter "commit" (or "abort"), but not
the individual queries within transactions. This happens simply because it's
hard to force individual queries to overlap; particularly when we're typing
them in manually. On a busy system, however, in which individual queries may
overlap, there's more that Postgres must do to make read-committed work
properly.
In terms of snapshots (below), read-committed is
implemented by, in addition to preventing reads of uncommitted data, also
taking snapshots of the database as of the start
of each separate query within the transaction. But as these
snapshots last only for the lifetime of each query, usually a few
milliseconds, their effect is not readily apparent. Additionally, each query
within the transaction is allowed to see its own previous effects, and the
effects of other transactions (and queries) that have committed by that
point; this is demonstrated by the examples above.
We will be able to see snapshots in action when we look at how the repeatable-read
isolation level is implemented, as these snapshots may last for many seconds
(for the lifetime of the transaction, to be specific).
Snapshots
The idea behind a snapshot is that the transaction (or individual query)
using the snapshot sees no updates or inserts that have not committed as
of the time the snapshot was taken. This is stronger than not reading
from uncommitted transactions: if T1 takes a snapshot, and then T2 commits,
and T1's snapshot is still in effect, then T1 does not see the T2's changes
even though T2 has committed.
For most purposes, snapshots are of importance only for Repeatable Read
isolation. Read Committed isolation uses snapshots, in effect, only if
individual queries within a transaction are not being executed
serially; this is rare. Serializable isolation uses snapshots the way
Repeatable Read does, plus other techniques (from the manual:
"[serializable] isolation level works exactly the same as Repeatable Read
except that it monitors for conditions which could make execution of a
concurrent set of serializable transactions behave in a manner inconsistent
with all possible serial (one at a time) executions of those transactions").
To implement a snapshot, Postgres records two things at the time the
snapshot is taken:
- The list of currently running (not yet committed) transactions
- The highest transaction number so far
All operations restricted to the snapshot are then not allowed to read
updates/inserts from transaction ids either in the list in 1 or greater
than the maximum in 2. That is, an operation within a snapshot can only
see changes that have committed before the snapshot was taken.
In order to do this, Postgres records for each tuple values xmin
and xmax:
- xmin is the transaction id of the transaction that
created the tuple
- xmax is the transaction id that deleted the tuple (if
any)
When searching the tuple chain during the course of the transaction, a
tuple is rejected if its transaction id is in the snapshot list of
transactions in progress but not yet committed as of the start of the
original transaction, or has xmin greater than the original transaction's
id (there is a similar rule for delete operations and xmax).
As an example, let's look at the transaction id and the employee records
this time with xmin (and xmax):
begin;
select txid_current();
insert into employee values ('Ralph', 'I', 'Wiggum', '123212321', null,
null, 'M', 23000, '888665555', 1);
select fname, lname, xmin, xmax from employee;
The transaction id equals Ralph's xmin! (Ralph has no xmax, because he
hasn't been deleted.)
The longer a snapshot is held, the more expensive it becomes to maintain
it, in terms of overhead. For the read-committed
isolation level, a separate snapshot is taken at the start of each
individual query within the transaction, and lasts only until that query
(for example, an update command) ends. In manual demonstrations,
individual queries take a few milliseconds each and so run fully
serialized (that is, there is no overlap). In this setting, the snapshot
plays no obvious role. In high-density transaction environments, however,
things are different.
For the simple read-committed-with-serialized-queries case, the only
effective constraint is that queries within a transaction are not allowed
to read tuples that have been written by other transactions that have not
yet committed. The snapshot data in 1 and 2 above is ephemeral.
As we shall see, the corresponding repeatable-read
rule requires that the snapshot be held for the lifetime of the
transaction; that is, until the user types "commit". In this case, we can
demonstrate with manual queries the snapshot behavior.
The xmin and xmax values are exactly what we need to maintain snapshots.
Recall that a tuple's xmin represents the id of the transaction that
inserted or updated the tuple. Any query within the lifetime of the
snapshot is not shown tuples with an xmin in the list in 1, or with an
xmin larger than the cutoff in 2, even if the other query creating the
tuple has committed; such tuples are outside the view of the snapshot.
Similarly, the transaction query is shown deleted tuples with an
xmax in the list in 1, or larger than the cutoff in 2. In the eyes of the
snapshot, those tuples are not yet deleted.
Most uses of snapshots also include a conflicting-write
provision to prevent two transactions from writing (append or
update) to the same data. So if a transaction wants to insert or update a
record, and another uncommitted transaction has already done this, the
second transaction must wait.
See https://momjian.us/main/writings/pgsql/mvcc.pdf.
Repeatable Read
To implement the repeatable-read isolation level, Postgres creates a
snapshot at the start of the transaction, and this snapshot persists for
the lifetime of the transaction. All queries within the transaction
are restricted to this initial snapshot. That is, the snapshot lasts until
the transaction commits, and so can last as long as we want. As an example,
let's do the earlier two-transaction salary-update demo with Ralph, but this
time T1 will request the Repeatable Read isolation level.
Ralph has already been inserted, with salary 23,000.
T1: begin;
set transaction isolation level repeatable read;
select salary from employee where lname = 'Wiggum';
Now we update Ralph's salary in a second transaction T2, as before. T2
may use the default read committed isolation level
T2: begin; update employee set salary = salary
+ 1000 where lname = 'Wiggum'; commit;
Does T1 see this updated salary? No!
T1: select salary from employee where lname =
'Wiggum';
This still returns 23,000, the salary in effect in the "snapshot" as of
the start of T1!
Now let's have T1 commit. After this, we do see the new salary
of 24,000.
Postgres implements all this by taking a snapshot of
the database at the time the transaction T1 starts, and using the snapshot
until the end of the transaction. This snapshot includes the transaction
ids of all transactions that were still active as of the start of T1. Any
updates made by those transactions (marked with xmin of their transaction
id) are not allowed to be seen by T1. Similarly, updates from any
transactions starting after T1 cannot be seen by T1 (That is, T1 will only
be able to see changes made by transactions that committed before
T1 started). The same applies to deletions, using xmax.
The other way to implement Repeatable Read isolation, not using
snapshots, is to use locks; MySQL does this. Locks usually create a
considerable performance bottleneck. The discovery of snapshot-based
Repeatable Read isolation was a significant advance. The Postgres group
was an early implementer of this approach.
Next let's do the conflicting salary updates with
repeatable-read for T1. T1 starts first,
T1: begin; set transaction isolation level
repeatable read;
and then T2 does the first salary update:
T2: update employee set salary = salary + 2000
where lname = 'Wiggum';
After that, but before T2 has committed (so T2 has to be a "real"
transaction; we cannot rely on autocommit), T1 issues its update request:
T1: update employee set salary = salary + 1000
where lname = 'Wiggum';
Again T1 hangs, because there is already an uncommitted write to this
record. If T2 aborts, T1 can finish, but not if T2 commits. If T2 does
commit, T1 immediately gets the error message
ERROR: could not serialize access due to
concurrent update
The same thing happens if T2 sets salary = 25000 and T1 tries to set
salary = 24000, that is, if a pure update is done rather than a
read-and-update.
This is a fact of life with repeatable-read: you have to be prepared to
retry a transaction.
In terms of tuples, after the T2 update we have two tuples for Ralph:
⟨Ralph,...,23000,..., xmin=0⟩
⟨Ralph,...,25000,..., xmin=T2_xid⟩
After T2 commits, the second tuple is marked as committed, but the first
tuple is still part of T1's snapshot and so is still active. If T1 had not
tried to update Ralph's salary, it could continue working, but it would
see the salary as 23000. T1's snapshot tuple (with the 23000) goes away
only when T1 commits (or aborts).
Finally, let's do the phantom-read example. T1 requests repeatable-read
isolation; T2 does not. T2 inserts num=3 into table numbers, and then
commits. T1 still cannot see this value. If T1 goes ahead and
inserts num=4, it will see values 1, 2 and 4. Once it commits, however, the
table will have values 1, 2, 3, and 4: there is no conflict between T1 and
T2 with the num=3 and num=4 insertions. With repeatable-read isolation,
phantom reads are allowed by the standard, but not by Postgres: within the
transaction, the transaction's view is governed by the snapshot as of the
start of the transaction.
Serializable
If repeatable-read transactions use a snapshot of the database as of the
start of the transaction, why can't we serialize them by start times /
transaction ids? The problem is that rows may be added. Here's an example
from the Postgres
documentation. We start with a two-column table:
create table mytab (class integer, value
integer);
insert into mytab values (1,10),(1,20),(2,100),(2,200);
We get:
class
| value
-------+-------
1 | 10
1 | 20
2 | 100
2 | 200
T1 will add up the values corresponding to class 1, namely 10+20 = 30, and
insert (2,30). Similarly, T2 will add up the values corresponding to class
2, namely 300, and insert (1,300). They will each do this in isolation from
one another. The added rows (2,30) and (1,300) do not conflict per se,
so repeatable-read isolation has no problem.
insert into mytab values (2, (select sum(value) from mytab where class=1));
insert into mytab values (1, (select sum(value) from mytab where class=2));
But this outcome is not the result of executing T1 first and then T2, or of
executing T2 first and then T1: the sums would change as the first
transaction's inserted record would affect the sum of the second
transaction.
If we run this with serializable isolation:
begin;
set transaction isolation level serializable;
then both inserts are allowed, as the records don't conflict directly. But
when the second transaction commits, we get
ERROR: could not serialize access due
to read/write dependencies among transactions
DETAIL: Reason code: Canceled on identification as a pivot, during
commit attempt.
HINT: The transaction might succeed if retried.
If, instead, we run this with repeatable-read isolation, we end up with both
new rows (2,30) and (1,300) inserted.
Postgres enforces the serializable isolation level by monitoring for query
dependencies that may be unserializable. In some cases, Postgres
can be "fooled" into blocking a transaction that in fact was serializable.
Locking
Locking is the basis for transaction-execution protocols
that guarantee a reasonable degree of serializability or other isolation.
We will only consider relatively simple locks; complex locks tend to be
inefficient. Simple locks are usually sufficient. A binary
lock has two states: locked
and unlocked. We can implement a
per-field/record/block/table lock with a locking
table; at any one time, we are likely to have relatively few locks.
When we lock something, we may have to wait.
See Fig 22.1. Ideally, we wait in a queue on the lock.
The actual inner details of lock()
and unlock() must be atomic. On
multi-processor systems, it is not
enough simply to disable interrupts, as the two processors can continue to
interact in unfortunate ways.
Most instruction sets have some operations that are guaranteed atomic,
such as a test-and-increment instruction. If X == 0, then a
test-and-increment instruction might set X=1; otherwise it would leave X
unchanged. A lock can now be constructed: the lock(X) operation attempts
test-and-increment on X. If it succeeds, that thread now holds the lock. If
it fails, then someone else holds the lock, and our thread must wait.
It
is important to note that test-and-increment cannot be split into multiple
interleaved accesses, of the form "if (X==0) X++". The processors can access
memory in the following fashion:
| processor 1 |
processor 2 |
| Load X |
Load X |
| confirm X==0 |
confirm X==0 |
| Store X=1 |
|
|
Store X=1 |
At the end of this sequence, both processors believe they hold the lock!
If there is no appropriate atomic CPU instruction, one can create a software
lock manager that runs on a single CPU; other CPUs make
locking requests to it. Sometimes, low-level locks like the above are used
only for synchronization of requests to the lock manager.
A typical lock-manager data structure is the lock table, listing, for each
locked data item D (attribute, record or table) the following information:
- the locked data item D
- whether the lock is a read-lock or a write-lock
- the transaction holding the lock (if it is a write lock) or the list
of transactions holding the lock (if it is a read lock)
- a list of transactions waiting on the lock
A straightforward improvement on binary locks is read-write
locks: write locks imply exclusive access, but several transactions
can read-lock the same data value concurrently. Sometimes read-lock(X) is upgraded
to write-lock(X). This can happen immediately upon request if the current
transaction is the only one holding read-lock(X); otherwise the current
transaction must wait for the other readers to finish.
General rules for locks are the following:
- A lock (read or write) must be obtained on X before read(X)
- A write lock must be obtained on X before write(X)
- X must be unlocked after a transaction is done with X
- Transactions should not issue multiple lock requests for the same X
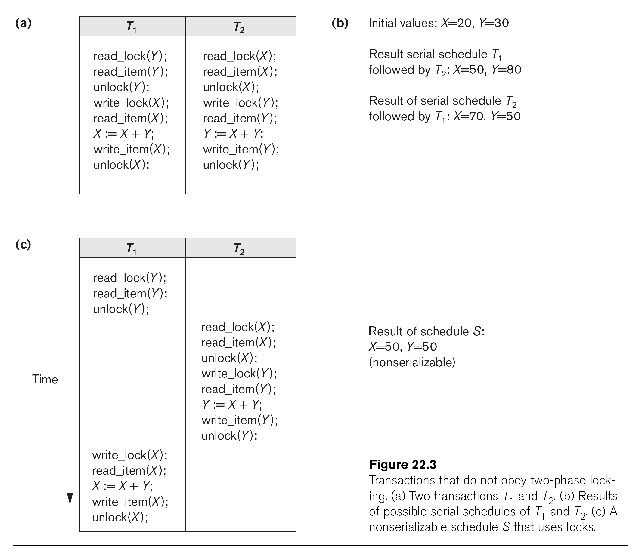
These rules do not guarantee serializability. Consider the following
(from fig 22.3); T1 and T2 have X and Y
reversed.
| T1 |
T2 |
read_lock(Y)
read(Y)
unlock(Y) |
|
|
read_lock(X)
read(X)
unlock(X)
write_lock(Y)
read(Y)
Y=X+Y
write(Y)
unlock(Y) |
write_lock(X)
read(X)
X=X+Y
write(X)
unlock(X) |
|
If initially X=20 and Y=30, then if we run T1 we have X=50 and Y=30;
running T2 then leaves us with X=50 and Y=80. Executing T2 first leaves us
with Y=50; then running T1 leaves us with X=70, Y=50.
But if we execute the transaction according to the schedule above, then
T2 writes Y=50, while T1 writes X=50. This is not equivalent to either
serial schedule!
The problem here is that T1 unlocked Y too soon (similarly, T2 unlocks X
too soon).
Two-phase locking
Two-phase locking is a simple protocol in which all locking operations
(including upgrades of read-lock(X) to write-lock(X)) precede the first
unlock operation. This fails for the transaction above.
The locking phase is called the expanding
phase; the unlock is the shrinking
phase.
If all transactions use two-phase locking, then
any schedule will be conflict-serializable. No loop-detection in
conflict graphs is needed.
Two-phase locking does limit concurrency, however, by forcing transactions
to hold locks for longer than they strictly need them.
There are some conflict-serializable schedules that can not be
realized if two-phase locking is used. This is generally of minor
importance.
Fig 22.4 shows the same transactions T1
and T2 using the two-phase locking protocol. Here, however, we have the
potential for deadlock.
Two-phase locking comes in flavors. The version above is called basic.
We also have:
- conservative: transactions
must lock all the items to be accessed at the start of the transaction.
This is deadlock-free, but sometimes the transaction does not know every
item to be read until partway through.
- strict: no write locks are
released until the transaction's commit/rollback. This means that no
other transaction that reads from this one can do so until the first one
has committed. This leads to a strict
schedule, which is then cascadeless.
Deadlocks may occur.
- rigorous: no locks at all are
released until commit/rollback. Rigorous two-phase locking is sort of a
mirror image of conservative two-phase locking.
Generally it is the concurrency-control subsystem of the database that
locks and unlocks items, and not the transactions themselves.
Deadlock
Locking protocols generally introduce the risk of deadlock
(see also Fig 22.4):
T1
|
T2
|
read_lock(X)
|
read_lock(Y)
|
write_lock(Y)
|
write_lock(X)
|
...
|
...
|
(The first row of locks can also be write locks). Each transaction above
must wait, at the point it requests its write lock, for the other. The
other, also waiting, never gives up its read lock.
Perhaps the simplest strategy for deadlock prevention is to lock everything
according to one master order. This is often impractical for the programmer,
or even the concurrency-control system, to enforce. One possible order,
though, might be to lock rows first by TableID and then by RowNum.
Conservative two-phase locking can also work as a deadlock-prevention rule:
all the locks are requested at the start, and, if any lock fails, all locks
are released and the transaction is tried again later. Recall, however, that
many transactions are unable to determine what locks they will need at the
start.
In practical terms, we also have to deal with deadlock detection,
and then decide which transaction will be aborted and which will wait. Note
that it soon becomes obvious in practice that deadlock has occurred: any
transaction that waits for more than a few seconds on a lock, and is not
moving up in the queue for that lock, is likely deadlocked.
Timestamps
An alternative to locks entirely is the use of timestamps. We assign each
transaction T a timestamp TS(T), and then only allow schedules that are
equivalent to executing the transactions in timestamp order. To do this,
each database item has associated with it a read-timestamp and a
write-timestamp; the former is the latest timestamp of all transactions that
have read X, and the latter is the latest timestamp of all transactions that
have written X. If a transaction T attempts read(X), we first compare T's
timestamp with read-timestamp(X). If T's timestamp is not later than
read-timestamp(X), we abort T and put it back in the transaction queue with
a later timestamp; ditto for write(X). This protocol can involve cascading
rollback, so further constraints are needed to get it to generate
cascadeless or strict schedules (or even recoverable schedules, for that
matter).
The wait-die protocol says that if T1 needs a
lock held by T2, then if TS(T1) < TS(T2)
-- so T1 is the older -- T1 is allowed to wait.
But if T1 is younger, it is aborted.
The wound-wait protocol says that if T1 needs
a lock held by T2, then if T1 is older we wound
T2: we abort it, but allow it to restart later with the same
timestamp (at which point T2 is likely to be older than
most if not all other transactions, and is less "woundable"). If T1
is younger, it is allowed to wait.
Wait-die allows the older transaction to wait for the younger. Wound-wait
allows the younger transaction to wait for the older
Other deadlock-prevention protocols are no-waiting and cautious
waiting. In the former, if a transaction cannot get a lock, it is
rescheduled for later, regardless of whether a deadlock would actually have
occurred. In cautious waiting, transaction T1
is allowed to wait for T2 to release a lock provided T2
is not itself waiting on any lock (that is, provided T2 is
not blocked). If T2 later is blocked, its blocking time
must occur after T1's. No cycle of blocked transactions can occur
because their blocking times form a linear order, and the one with the
latest blocking time cannot be waiting for any of the earlier blockers.
Deadlock Detection
One simple approach to deadlock detection is to declare a transaction
deadlocked if it has waited for more than a certain modest amount of time;
this is called timeout detection. MySQL does this. Note
that this is not "true" deadlock detection. But if I do the following in
separate windows
start transaction;
insert into employee values ('Ralph', 'I', 'Wiggum', '123212321', null,
null, 'M', 23000, '888665555', 1);
start transaction;
insert into employee values ('Clarence', 'c', 'Wiggum', '123212321', null,
null, 'M', 33000, '888665555', 1);
Then eventually (~50 seconds on my system) one dies and I get
ERROR 1205 (HY000): Lock wait timeout exceeded; try
restarting transaction
Postgres handles the above a little better: for either Read Committed or
Repeatable Read isolation, the second transaction simply waits.
We can trigger a Postgres deadlock, though, as follows:
| T1 |
T2 |
| start transaction; |
start transaction; |
| update employee set salary = 26000 where lname = 'Jabbar'; |
|
|
update employee set salary = 26000 where lname = 'English'; |
| update employee set salary = 27000 where lname = 'English'; |
|
|
update employee set salary = 27000 where lname = 'Jabbar'; |
Postgres' response, with a delay of about a second, is
ERROR:
deadlock detected
DETAIL: Process 26340 waits for ShareLock on transaction 11994;
blocked by process 26374.
Process 26374 waits for ShareLock on transaction 11995; blocked by
process 26340.
HINT: See server log for query details.
CONTEXT: while updating tuple (0,8) in relation "employee"
The isolation level does not matter.
It is also possible to detect deadlocks by constructing a wait-for
graph, and look for cycles. In the wait-for graph, there is an arrow from T1
to T2 if T1 is waiting for a lock on an item that T2
has locked. An edge T1⟶T2 is dropped once T2
releases its locks. A cycle in this graph means a deadlock has been found.
Practical implementations may limit how often this graph is constructed and
checked.
After a deadlock is identified, there is the decision of victim
selection: which transaction will be aborted.
Even in deadlock-free environments, transactions can face starvation
waiting for locks . Suppose, for example, that the concurrency subsystem
always grants additional read-locks on items as long as an existing
read-lock is in place. A transaction waiting for a write-lock may have to
wait "forever", if new readers keep coming up. This is known as the readers-and-writers
problem. Making new read-lock requests wait until the write-lock request has
completed has other problems.
Timestamps
Timestamps can also be used for concurrency control. The goal is to execute
transactions Ti in an order that is conflict-equivalent to
executing them serially in order of their timestamps TS(Ti). With
no locks, this scheme is deadlock-free.
To get timestamps to work this way, each active database item X has two
values:
- read_TS(X): the largest (most recent) timestamp of any transaction T
that has executed read(X)
- write_TS(X): the largest timestamp of any transaction that has
executed write(X)
Now, if transaction T attempts read(X), the algorithm compares TS(T) with
read_TS(X). If read_TS(X) is newer (larger), then T is aborted and
rescheduled later with a larger timestamp. If write_TS(X) > TS(T), then
we drop its write(X) operation, on the theory that X would be overwritten
anyway by the transaction T2 with TS(T2) =
write_TS(X). This looks disturbing, but an actual read-write conflict
would have been detected with the read_TS(X) case.
MyISAM v InnoDB
At the time the MySQL InnoDB engine was introduced, the older MyISAM engine
was often considered to be faster. However, for many purposes, the actual
situation is more nuanced. One big difference between MyISAM and InnoDB is
that the former supports only table locking, while the
latter supports row locking. This is sometimes described
as MyISAM having coarse lock granularity while InnoDB has
fine granularity. The end result is that, if updates to
specific rows are involved, MyISAM will have to enforce strict serialization
while InnoDB can allow multiple updates on multiple different
rows to proceed in parallel.
InnoDB also supports many other new features, among them the following:
- better support for ACID transactions
- log-based crash recovery (below)
- "hot" backup support (backups while the DB is running)
- More engine-tuning options
InnoDB supports a wide range of tuning options, involving the extent of
logging, how memory and disk space are allocated, how buffer pools are
managed, how best to interact with the underlying operating system (which
has its own tuning options, such as filesystem type, for example).
A good Percona blog on some of these techniques is here.
Overall, transaction conflict (in the sense above) is a significant
bottleneck. For many real databases, the only reason they can do multiple
transactions is that most transactions don't conflict. Customer 1's invoice
may have little to do with Customer 2's, in most respects.
The biggest problem for invoices is often the update of the quantity
remaining in stock. If it is a requirement that customers are never
disappointed, then each customer's transaction must include a set of
operations of the form
select quantity_in_stock from Parts where partnum =
'123456';
update Parts set quantity_in_stock = quantity_in_stock -
just_sold where partnum = '123456';
Records for all partnums purchased must be locked for the
duration of the set of updates.
EN6 includes a discussion in 22.5.2 about support for both coarse and fine
lock granularity.
MyISAM doesn't support transactions per se. If we run the following
start transaction;
insert into employsam values ('Ralph', 'I', 'Wiggum', '123212321', null,
null, 'M', 23000, '888665555', 1);
rollback;
on table employsam that uses engine MyISAM, it enters Ralph permanently.
Indexes and Locking
If a B-tree is accessed with the goal of inserting a record, a naive
write lock would apply to the entire structure, tying up the root node in
particular until the lock was released. A more careful strategy is to
create special lock protocols for indexes. Locks on upper levels of the
index can be released as soon as it is clear that those levels will not be
written to, and that whatever goes on at lower levels won't affect upper
levels.
This is not completely trivial: insertion of a leaf node into a B-tree
can indeed create a new root node. However, if we can determine that there
is a node with sufficient room for insertion, then any sequence of "value
push-ups" will go no higher, and the upper parts of the tree can be
unlocked.
Crash Recovery
A crucial feature of transactions (the "atomic" property) is that if the
database crashes, or is restarted (eg due to deadlocks), or one transaction
fails, then no transaction is left "partially" executed: every transaction
either completes or is rolled back.
The typical way to implement this is with a transaction journal
file, sometimes known as a redo log, which is
carefully written to disk after every update. This journal might contain:
- a transaction ID
- original values of the data fields to be updated
- a flag indicating that the transaction is pending
The flag is set to "committed" at the end. Then, if the DB is restarted
after a crash, we can restore the records involved to their pre-transaction
state.
Note that we also will now need to roll back any other transaction that
depended on this one; we can use the transaction ID for that.
Different databases (eg MyISAM v InnoDB v MongoDB) handle these recovery
journals in different ways. There are I/O performance differences, and also
some differences in terms of just what can be recovered from.
Transactions per second
What is a good number? The pgbench tool can be used to run Postgres
benchmarks. To initialize, create a database named pgbench and then, as
system user postgres, run "pgbench -i pgbench". When I then run
pgbench -c 25 -j 25 -t 400 pgbench #
25 threads, 400 transactions per thread
I get (in 2024)
tps = 1250
That's one transaction in 0.8 ms.
What about, say, Amazon? The tps rate at Amazon isn't quite as high as
one might think, though Amazon doesn't like to publish figures. In 2016,
Amazon hit 600
items per second. In 2017, during the post-Thanksgiving five-day
sales period they hit maybe 200
million items in 120 hours, for about 400-500 items/second. Other
sources suggest 300 transactions per second for a peak rate.
My transaction demo
We will simulate multiple users buying things online by creating multiple
Python threads to perform transactions, and measuring the transactions per
second.
Here are the tables of my transactions database; this is the classic
four-table structure used (with slightly different names) in the Dellstore
example.
- customer(custid serial, custname varchar(20))
- part (partnum serial, price decimal, quan_in_stock integer)
- invoice (invnum serial, ordertime timestamp, custid integer,
totalamt decimal)
- invitem(invoicenum integer, partnum integer, quantity
integer)
Here is my typical transaction, generated by my Python script below, and
based on input custid, part1, quan1, part2, quan2:
begin;
insert into invoice(ordertime, custid) values (now(), custid);
insert into invitem values (invnum, part1, quan1);
update part set quan_in_stock = quan_in_stock - quan1 where partnum =
part1;
insert into invitem values (invnum, part2, quan2);
update part set quan_in_stock = quan_in_stock - quan2 where partnum =
part2;
...
commit;
Actual transactions have ten items, making ten parts updates (rather than
the two parts updates shown above)
The transaction "insert into invoice" is not the problem, unless the same
customer places dozens of orders per second. The "insert into invitem" is
also generally safe, as there should never be more than one transaction
operating on a given invnum (why?). It's the "update part" that is the
bottleneck issue, as this must lock that record of the part table.
Here are the files:
Between experiments we really should clean out the invoice and invitem
tables, but that can be complicated due to foreign-key constraints. Start
with invitem and partupdate; then delete from invoice. It does not make a
significant difference.
These experiments are done with either MAXPART = 50 (lots of contention,
as everyone is ordering the same parts), or 500 (less contention).
Occasionally we may need to restock:
update part set quan_in_stock = 1000;
Experiment 1: true serial execution
Run conndemo.py with NUMTHREADS=1, PERTHREAD=1000. (We don't need to
enable isolation level serializable,
as we're just going to run the transactions serially)
python3
conndemo.py postgres
This took ~5-6 seconds for 1000 transactions, or about 180 tps. That's
not the whole story, though; each transaction does 5 updates to the table
part. (Also some updates to invitem.) This works out to
somewhere in the ballpark of 1000 tps.
Experiment 2: lots of parallelism
Try with (NUMTHREADS, PERTHREAD) = (25,40), and also and also SORT=False
and REQLOCKS=False. We get lots of deadlock messages, due do transactions
waiting for one another. The number of invitem entries will be less than
10,000, due to overlap. The conndemo.py program prints at the end the
total parts quantity; this should equal the change in select
sum(quantity) from invitem;. Here is one typical deadlock message
(MAXPART = 500):
transaction
failed: ERROR: deadlock detected
DETAIL: Process 707 waits for ShareLock on transaction 211312;
blocked by process 703.
Process 703 waits for ShareLock on transaction 211310; blocked by
process 707.
HINT: See server log for query details.
CONTEXT: while updating tuple (26,148) in relation "part"
Try with (2,500): still some deadlock
This is very dramatic with NUMTHREADS = 4 and with MAXPART = 50. In 2024,
I got 171 seconds, almost three minutes (the in-class demo had TOTALTRANS
reduced from 1000 to 200 so it would run in a reasonable amount of time.
Surprisingly, with NUMTHREADS = 2 rather than 4 there can be very little
contention.)
Experiment 3: Requesting locks
Let's try asking for the locks upfront, with REQLOCKS=True. Postgres lets
us ask for a lock on a specific record (with partnum = %s, where %s here
serves as a variable) with
select partnum
from part where partnum = %s for update;
According to the Postgres manual, "FOR UPDATE
causes the rows retrieved by the SELECT
statement to be locked as though for update. This prevents them from being
locked, modified or deleted by other transactions until the current
transaction ends."
We can, by the way, lock an entire table (eg part) with the
following (though we do not)
- lock part in share row exclusive mode
- lock part in exclusive mode
- lock part in access exclusive mode
If NOWAIT is false, then each transaction waits for each lock in
turn. If a lock fails, the request deadlocks, and we start the lock
request over.
To summarize the values:
- MAXPART = 500
- NUMTHREADS=25
- PERTHREAD=40
- REQLOCKS=True
- NOWAIT=False
- SORT=False
This works, but often takes 20-40 sec!
In this scenario, when a transaction can't get its locks, it aborts (with
a deadlock!) and tries again immediately. But for each lock, it waits to
see if it will be granted, or if the existing locks will lead to a
deadlock. Should we wait between tries a little bit? If so, how long?
Should it put the transaction back to the end of that thread's queue? We
don't really have a queue. (Note that the lock requests may
deadlock, but then we just handle the exception, silently, and try again.)
Try enabling that print statement in the first exception handler
What happens when we reduce RETRYCOUNT? We can go to 5, and it still
usually works. The Python script runs almost silently, with almost no
transaction failures. But my 2024 time was ~120 seconds.
If we set NOWAIT=True, we get a handful of lock
failures (look for the "lockfails" count in each "Exiting thread"
report), and a failure of the total parts quantity to be reflected in the
database. The total elapsed time, however, is down to 4-5 seconds again.
In this scenario, we ask for the locks in
rapid succession, but if any lock can't be granted immediately, we release
all locks and immediately try again.
We now need a much higher value of RETRYCOUNT;
at least 20. Should we make it really big?
But look what happens to the total time! Much
better! ~100 tps.
Changing to REPEATABLE READ does not make much
difference.
Experiment 4: Sorting the updates
Now let's enable sorting the part numbers in each
transaction. No problems! Total time is 1.6 seconds. Why does
this work? Now that we're requesting locks in increasing order
of part number, we are deadlock-free.
- MAXPART = 500
- NUMTHREADS=25
- PERTHREAD=40
- REQLOCKS=True
- NOWAIT=False
- SORT=True
Try:
- with/without NOWAIT
- with/without REQLOCK
- ISOLATION='repeatable read'
- ISOLATION='serializable'
250 tps is not bad. But how does Amazon do it? How could you speed this
up?
- partitioning the parts database
- entering sales in a separate table, and then updating the parts table
at intervals
- accepting some potential non-atomicity
Experiment 4.5: try the above but with REPEATABLE READ.There are a lot
more transaction failures, and a total time of about 3.2 seconds.
Experiment 5: table partupdate.
This has the following definition:
create
table partupdate (
invnum integer,
partnum integer,
quan_sold integer,
constraint partupdate_invnum foreign key
(invnum) references invoice(invnum),
constraint partupdate_partnum foreign key (partnum)
references part(partnum)
);
Instead of updating the quan_in_stock entry of table part, we create in
table partupdate a record (invnum, partnum, quansold). We will then update
part.quan_in_stock from this partupdate record at some later date,
as part of a "batch" update to table part.
This flirts with atomicity failure, in that part.quan_in_stock may not be
accurate. However, if the partupdate record is safely written, we
shouldn't risk loss of updates.
The point of all this is that appending records to partupdate should not
require locks. Because we include invnum, two different transactions
should never be trying to insert the same record.
But we're still at around 4000 ms for 1000 transactions (250 tps).
My file here is conndemo3.py.
Every so often we need to run the following transaction to migrate all
the partupdate data into part:
begin;
with sums as
(select p.partnum, sum(p.quan_sold) as numsold from partupdate p where
p.partnum = PARTNUM group by p.partnum) -- summarize partupdate
data
update part p set quan_in_stock = quan_in_stock - (select s.numsold from
sums s where s.partnum = p.partnum) from sums where p.partnum =
sums.partnum;
delete from partupdate;
commit;
Note that we do not need a "foreach partnum that has seen some
sales, update part ...." loop.
Experiment 6: table locks
If each transaction locks the entire parts table with
lock part in exclusive mode;
then the 1000 transactions (25 threads) takes 7-8 seconds, for about
125-135 transactions per second. Exclusive table locks, in other words, do
slow things down, versus the best version we could do with row locks. The
file is cdtablelock.py.
{kind=link}