Comp 353/453: Database Programming, Corboy
523, 7:00 Thursdays
Week 10, Mar 29
Read in Elmasri & Navathe (EN)
- Chapter 15, Normalization
- PHP and debugging
- lamp.cslabs.luc.edu
Demo of setting up your db on lamp.cslabs.luc.edu, using company.lamp.text.
The steps:
- log in to lamp.cslabs.luc.edu
- copy company.lamp.text, above, to your current directory
- log in to mysql, using mysql -p
and password pNNNNN
- verify your database exists, if necessary ("show databases").
Your database name should be the same as your UVID.
- use your database, eg: use
pdordal (for me; substitute your own db name!)
- use the command source
company.lamp.text to load in the company db, creating the tables
and entering the data
- now set up a php directory (in your public_html directory) and
copy my starter *.php files there
- set the $database and $password fields to the proper values
(eg your uvid and pNNNNN)
- if you have to rebuild everything, be sure to set foreign_key_checks=0 first, then
start in with drop table employee,
etc
When using amp.cslabs.luc.edu, you will probably want to enable ssh publickey authentication.
From
http://php.net/manual/en/pdo.prepare.php:
public at grik dot net
07-Mar-2012 12:23
With PDO_MYSQL you need
to remember about the PDO::ATTR_EMULATE_PREPARES option.
The default value is TRUE, like
$dbh->setAttribute(PDO::ATTR_EMULATE_PREPARES,true);
This means that no prepared statement is created with
$dbh->prepare() call. With exec() call PDO replaces the placeholders
with values itself and sends MySQL a generic query string.
The first consequence is that the call
$dbh->prepare('garbage');
reports no error. You will get an SQL error during the $dbh->exec()
call.
The second one is the SQL injection risk in special cases, like using a
placeholder for the table name.
The reason for emulation is a poor performance of MySQL with prepared
statements. Emulation works significantly faster.
I became suspicious when I added better error checking to
employees.php, and discovered that misspelled table names did not cause errors in
$db->prepare($query). Sure enough, I activated the MySQL query log
and found the following:
61 Connect
pld@localhost on company
61 Query insert into employee values
('ralph','j','wiggums','abcdefghi','1980-07-04','no fixed
abode','M','9999','999887777','4')
Note that even the 9999 and the 4 are in quotation marks. More
importantly, there is no mention of prepare()
being called.
So I found the message above, and disabled preparation-emulation. The
MySQL query log then showed:
67 Connect
pld@localhost on company
67 Prepare insert into employee values
(?,?,?,?,?,?,?,?,?,?)
67 Execute insert into employee values
('ralph','j','wiggums','abcdefghk','1980-07-04','no fixed
abode','M','9999','999887777','4')
The fact that the query is being passed to MySQL with parameters quoted
and inserted does make me wonder, except that message comes from MySQL
after the query has been processed. Also, I now get errors from the
prepare() calls, when the query is mal-formed, rather than only at the
exec calls.
In the revised employees.php, I've left in the call to enable prepared
statements (ie to disable emulation), but it's commented out.
PHP notes
1. I edited
employees.php to include better error
checking. After each prepare(), execute() or query() I called either
$db->errorInfo() or $stmt->errorInfo(), and selected item [2] of
the returned array for printing.
Note that $db->prepare() returns either a PDOStatement object or
FALSE; if the latter you must call $db->errorInfo().
$db->query() always returns a Boolean; if it is FALSE then the
explanation is at ($db->errorInfo())[2]
(which expression is actually illegal in PHP; you need to break it up
as I did in employees.php). Finally, $stmt->execute() also always
returns a Boolean; if FALSE then the explanation is at $stmt->errorInfo(),
item [2]. While they work the same way, $db->errorInfo() and
$stmt->errorInfo() are methods of different classes.
Checking prepare(),etc results for equality with FALSE does not
involve any kind of type shenanigans; these methods either return a
PDOStatement object or a Boolean (you can't do that in Java, now, can you).
(Checking $_POST['submit'] as if it
were a Boolean does involve
some built-in type casts; if the submit
button was not defined then $_POST['submit'] is technically undefined,
or maybe NULL.)
The current employees.php is the new version with the improved error
checking. The old version is here: employees_noerrchk.php.
2. Note that your
php file is executed from scratch on each web click.
There's no easy way to store any state between clicks. In particular,
you have to connect to the database each time.
3. While you can put
PHP variables into print statements (including heredoc print statements)
print ("<b>Error:
$errormsg</b><p>\n");
you can not put expressions
into print statements; that is, you can't do
print("$db->errorInfo()<p>/n").
You also apparently cannot even do this:
$errmsg = ($db->$errorInfo())[2];
You have to break up the method call and the array access to separate
statements:
$errArray = $db->$errorInfo();
$errmsg = $errArray[2];
4. I updated
de_ralph($db). The new version restores table employee from table
employeebackup, which, of course, must exist for this to work.
I also had to turn off FK checking ("set foreign_key_checks=0"). You
only need to do this if you
create the tables using innodb, which I recommend. I had four steps:
- set foreign_key_checks=0
- delete from employee
- insert into employee select * from employeebackup
- set foreign_key_checks=1
I strung all these together into one monster query and sent that off to
MySQL. The new problem is that my error-checking only reports errors
from the last query in the chain, but if anything is going to go wrong
it is #2, "delete from employee", which will break some FK constraints.
I should have done each one separately, or at least #2.
In light of all this, the default
de_ralph() on the web page is still the old one.
By the way, the above can still break FK constraints even if it
executes properly. How?
5. I now have a
working makeSelectMenu. In the form makeSelectMenuString, it returns a
string that you can put into a heredoc block. The parameters for
makeSelectMenuString are the form-object name (used for retrieving
POSTed data) and an array of values. Here's an example creation of an
array of department numbers:
$query = "select dnumber from
department";
$retstmt = $db->query($query);
if ($retstmt == FALSE) { /* usual error-checking */ }
$values = $retstmt->fetchAll(PDO::FETCH_COLUMN);
$menustring = makeSelectMenuString("dno", $values);
Java option?
Functional Dependencies and Normalization
A functional dependency is a kind of semantic
constraint.
If X and Y are sets of attributes (column names) in a relation, a
functional dependency X⟶Y means that if two records have equal values
for X attributes, then they also have equal values for Y.
For example, if X is a set including the key attributes, then X⟶{all
attributes}.
Like key constraints, FD constraints are not based on specific sets of
records. For example, in the US, we have {zipcode}⟶{city}, but we no
longer have {zipcode}⟶{areacode}.
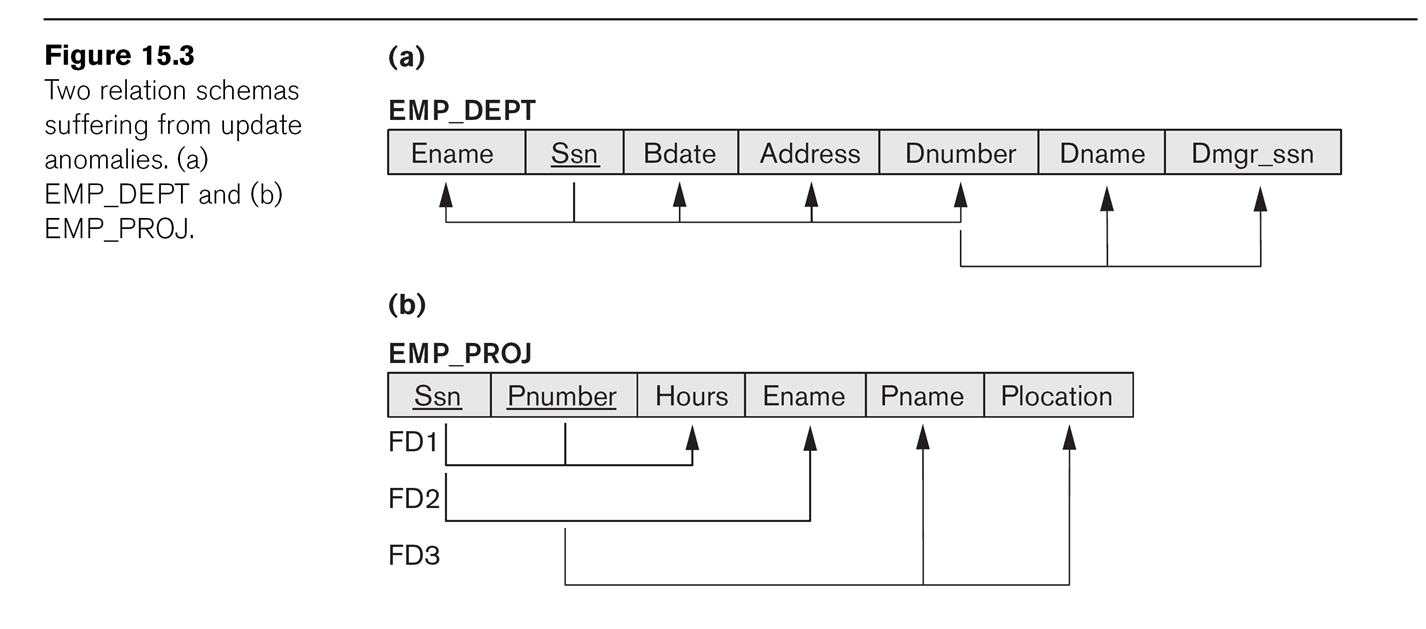
In the earlier EMP_PROJ, we have FDs
Ssn ⟶ Ename
Pnumber ⟶ Pname, Plocation
{Ssn, Pnumber} ⟶ Hours
In EMP_DEPT we have FDs
Ssn ⟶ Ename, Bdate, Address, Dnumber
Dnumber ⟶ Dname, Dmgr_ssn
Sometimes FDs are a problem, and we might think that just discreetly
removing them would be the best solution. But they often represent
important business rules; we can't really do that either.
A superkey (or key superset) of a relation schema
is a set of attributes S so that no two tuples of the relationship can
have the same values on S. A key
is thus a minimal superkey:
it is a superkey with no extraneous attributes that can be removed. For
example, {Ssn, Dno} is a superkey for EMPLOYEE, but Dno doesn't matter
(and in fact contains little information); the key is {Ssn}.
Note that, as with FDs, superkeys are related to the sematics of the
relationships, not to particular data in the tables.
Relations can have multiple keys, in which case each is called a candidate key.
For example, in table DEPARTMENT, both {dnumber} and {dname} are
candidate keys. For arbitrary performance-related reasons we designated
one of these the primary key;
other candidate keys are known as secondary
keys.
A prime attribute is an
attribute (ie column name) that belongs to some candidate key. A nonprime
attribute is not part of any key.
A dependency X⟶A is full if
the dependency fails for every proper subset X' of X; the dependency is
partial if not, ie if there is a proper subset X' of X such
that X'⟶A.
Normal Forms and Normalization
Normal Forms are rules for well-behaved relations. Normalization is the
process of converting poorly behaved relations to better behaved ones.
First Normal Form
First Normal Form (1NF) means that a relation has no composite
attributes or multivalued attributes. Note that dealing with the
multi-valued location
attribute of DEPARTMENT meant that we had to create a new table
LOCATIONS. Composite attributes were handled by making each of their
components a separate attribute.
Alternative ways for dealing with the multivalued location attribute
would be making ⟨dnumber, location⟩ the primary key, or supplying a
fixed number of location columns loc1, loc2, loc3, loc4. For the latter
approach, we must know in advance how many locations we will need; this
method also introduces NULL values.
Second Normal Form
Second Normal Form (2NF) means that, if K represents the set of
attributes making up the primary key, every nonprime
attribute A (that is an attribute not a member of any key) is
functionally
dependent on K (ie K⟶A), but that this fails for any proper subset of K
(no proper subset of K functionally determines A).
Note that if a relation has a single-attribute primary key, as does
EMP_DEPT, then 2NF is automatic. (Actually, the general definition of
2NF requires this for every candidate key; a relation with a
single-attribute primary key but with some multiple-attribute other key
would still have to be checked for 2NF.)
We say that X⟶Y is a full
functional dependency if for every proper subset X' of X, X' does not functionally determine Y. Thus,
2NF means that for every nonprime attribute A, the dependency K⟶A is full: no nonprime attribute depends
on less than the full key.
In the earlier EMP_PROJ relationship, the primary key K is {Ssn,
Pnumber}. 2NF fails because {Ssn}⟶Ename, and {Pnumber}⟶Pname,
{Pnumber}⟶Plocation.
To put a table in 2NF, decompose it into sets of attributes which all
have a common full dependency on some subset K' of K. For EMP_PROJ,
this becomes:
⟨Ssn, Pnumber, Hours⟩
⟨Ssn, Ename⟩
⟨Pnumber, Pname, Plocation⟩
Note that Hours is the only attribute with a full FD on {Ssn,Pnumber}.
The table EMP_DEPT is in 2NF.
Note that we might have a table ⟨K1, K2, K3, A1, A2, A3⟩, where
{K1,K2,K3}⟶A1 is full
{K1,K2}⟶A2 is full (neither K1 nor K2 alone
determines A2)
{K2,K3}⟶A2 is full
{K1,K3}⟶A3 is full
{K2,K3}⟶A3 is full
The decomposition could be
⟨K1, K2, K3, A1⟩
⟨K1, K2, A2⟩
⟨K1, K3, A3⟩
or it could be
⟨K1, K2, K3, A1⟩
⟨K2, K3, A2, A3⟩
Remember,
dependency constraints can be arbitrary! Dependency
constraints are often best thought of as "externally imposed rules";
they come out of the user-input-and-requirements phase of the DB
process. Trying to pretend that there is not a dependency constraint is
sometimes a bad idea.
Consider the LOTS example of Fig 15.12.
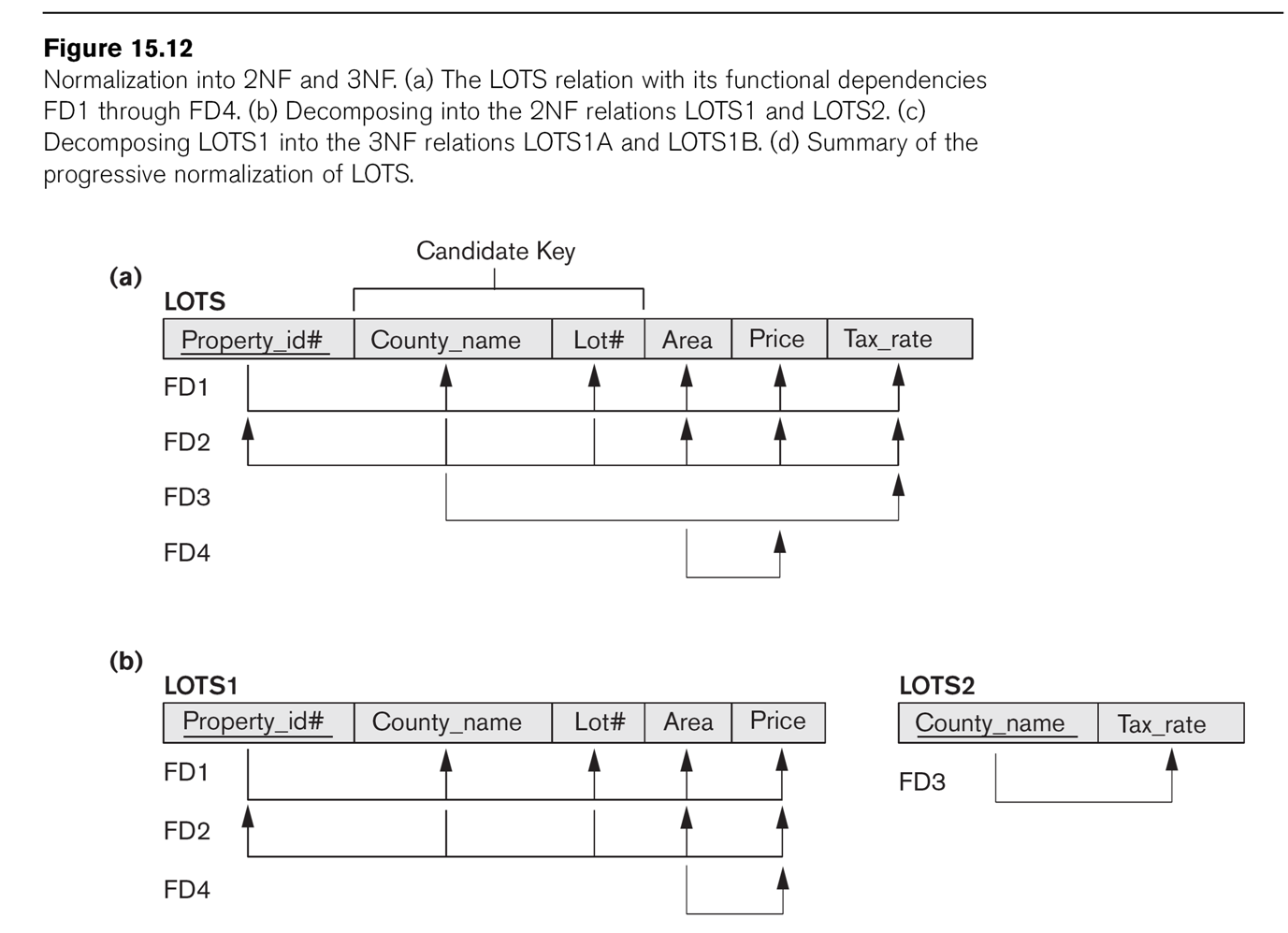
Attributes are
- property_ID
- county
- lot_num
- area
- price
- tax_rate
The primary key is property_ID, and ⟨county,lot_num⟩ is also a key.
These are functional dependencies FD1 and FD2 respectively. We also
have
FD3: county ⟶ tax_rate
FD4: area ⟶ price
(For farmland, FD4 is not completely unreasonable, at least if price
refers to the price for tax purposes. In Illinois, the formula is price
= area × factor_determined_by_soil_type).
2NF fails because of the dependency county ⟶ tax_rate. E&N suggest
the decomposition into LOTS1(property_ID, county, lot_num, area, price)
and LOTS2(county, tax_rate).
We can algorithmically use a 2NF-violating FD to define a decomposition
into new tables. If X⟶A is the FD, we remove A from table R, and
construct a new table with attributes those of X plus A.
Before going further, perhaps two points should be made about
decomposing too far. The first is that all the functional dependencies
should still appear in the set of decomposed tables; the second is that
reassembling the decomposed tables with the "obvious" join should give
us back the original table, that is, the join should be lossless.
A lossless join means no information is lost; typically, if the join is
not lossless then we get back all the original records and then some.
In Fig 15.5 there was a proposed decomposition into EMP_LOCS(ename,
plocation) and EMP_PROJ1(ssn,pnumber,hours,pname,plocation). The join
was not lossless.
Third Normal Form
Third Normal Form (3NF) means that the relation is in 2NF and also
there is no dependency X⟶A for nonprime attribute A and for attribute
set X that does not contain
a candidate key (ie X is not a superkey). In other words, if X⟶A holds
for some nonprime A, then X must be a superkey. (For comparison, 2NF
says that if X⟶A for nonprime A, then X cannot be a proper subset of
any key, but X can still overlap with a key or be disjoint from a key.)