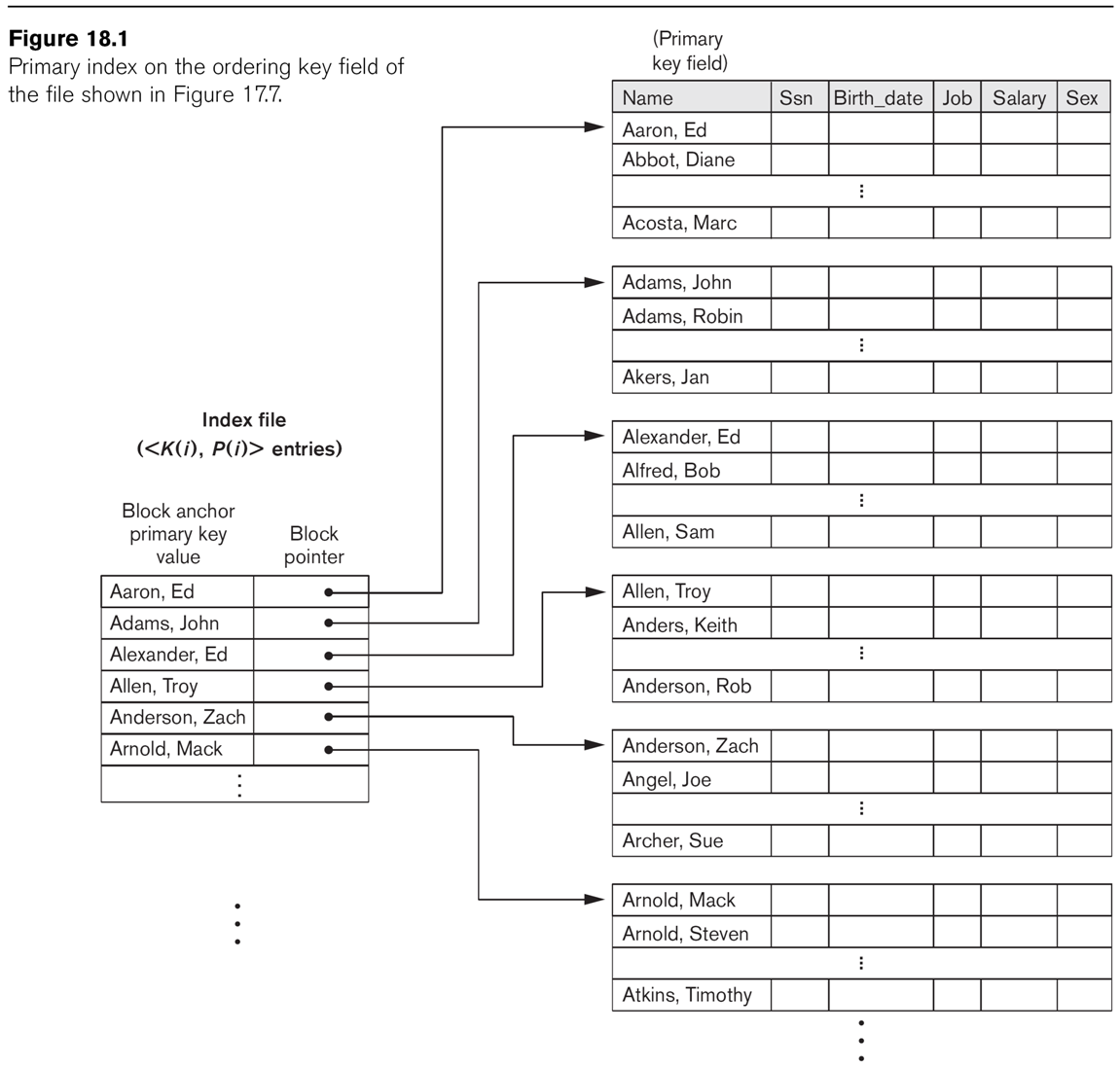
| index on | file ordered by | example | ||
| key value (primary index) |
that key value | sparse | fig 18.1 | |
| key value (secondary key?) |
something else | dense | fig 18.4 | |
| nonkey value (clustering) |
that nonkey value | sparse | figs 18.2, 18.3 | |
| nonkey value (clustering) |
something else | sparse | fig 18.5 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}