The primary goal of this course is to understand the internals of a computer system, and the ways these affect programming.
A secondary goal is to gain some basic familiarity with the C language.
The basic unit of information is the bit, a value that is either 0 or 1. All information in a computer is formatted in bits.
The byte (or, for some purists, the octet), is a group of 8 bits. Generally this is the smallest quantity that can be addressed individually.
Most modern computers also recognize the word, which can be 2, 4 or even 8 bytes. Nominally, a word is the amount of memory needed to store an address (BOH3 2.1.2). If the word size is 4 bytes, for example, or 32 bits, then an address can have up to 232 different values, which is 4,294,967,296. This is the maximum amount of memory that can be addressed; it represents 4 GB. That's not necessarily enough these days, hence the rise of the 64-bit word size.
A word used to represent an address is often called a pointer, or, in languages like Java, a reference. If we create a new object in variable x,
Foo x = new Foo()
then x is actually a one-word quantity representing the address of the Foo object. This has some ramifications: what is the result of the following code?
Foo x = new Foo(1);
Foo y = new Foo(2);
x = y;
System.out.println(x); // kind of a
fudge, but close enough
The assignment "x=y" assigns x to point to the same location as y. We can carry this a little further with set() and get() operations:
x=y;
y.set(3);
System.out.println(x.get()) // what
we should have done above
The variables x and y point to the same object, so if we change the object pointed to by y to contain the value 3, that's also what we see in x.
A computer's addressable memory is called random-access memory, or RAM. It's called random-access because you can read from any address and it takes the same amount of time; compare this to data on, for example, magnetic tape, where to read the Nth byte takes N reads total, longer and longer as N gets bigger. When we get to cache memory, we'll see that "random access" is not always the full story.
The computer reads memory by placing the address to be read in a special register; the value of the memory at that address (byte or word) is then retrieved and placed in another register. Writing is similar. Of course, these are very low-level operations; in programming languages we just use the variable.
RAM chips are usually dynamic RAM. This is much cheaper than so-called static RAM, but also slower. Still, it's fast enough for most purposes. Each RAM chip holds one bit, at each possible address; we need 8 chips to store bytes. If you look at DRAM modules, they usually have 8 chips (sometimes 9, for error correction).
Data stored in memory can be:
Arrays are just a sequence of equal-sized "things" in memory, laid out consecutively. We can access an array element by giving its position in the array, rather than the "raw" address.
Programs are also stored in memory. They consist of a sequence of machine-language opcodes, or instructions, each with, potentially, some supplemental information.
A computer runs programs by executing instructions in the central processing unit, or CPU. The CPU consists of some registers for storing words of data, an arithmetic-logical unit or ALU for actual calculations, and an interface to memory and other peripherals. Most instructions belong to one of these four categories:
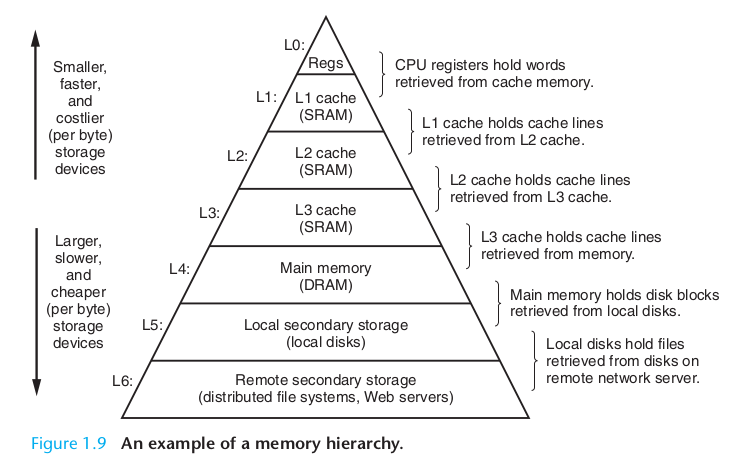
Here's the basic diagram of a computer, from BOH:
The term bus is used to refer to any internal computer communications link. Early busses involved multiple parallel lines, one for each bit being communicated, though single-wire "serial" busses (one bit after another) are now also common. However, a typical CPU bus has a number of lines equal to the word size.
There is a special register called the program counter, or PC, which holds the address of the next instruction to execute. Here is a basic outline of instruction execution:
Generally, disks can read data in the range of 100 MB/sec (maybe 200 MB/sec for a solid-state disk, or SSD). That sounds fast, but it is not as fast as DRAM, which has read speeds around 5 GB/sec for sustained reads (DDR3). This means that the I/O Bridge in the diagram above is doing a lot more work talking to RAM than talking to anything else.
On Intel-based systems, the I/O bridge is divided into the northbridge, which talks to RAM, and the southbridge, which talks to everything else.
DRAM is fast, but not as fast as the CPU. A modern CPU runs at a "clock speed" of around 3 GHz, meaning it executes 3 instructions per nanosecond (this is a bit optimistic, but never mind for now). But RAM may take tens of nanoseconds to load or store individual values; this can easily be 100 clock cycles.
The solution is the cache: a hardware device that contains little snippets of RAM stored on the CPU (or close) in so-called static RAM. The CPU looks for data first in the cache; if it finds it, the access time can be as little as one clock cycle. See BOH Fig 1.8.
Caches are a big deal. They improve performance tremendously. Modern systems use multiple layers of caches:
Caches work because of the principle of locality: if a program accesses data at one location, it's likely to access data at a nearby location in the immediate future. So, instead of loading just the byte at the given address, we might load 8 bytes (a typical Intel cache-line size), or even a multiple of 8 bytes. That way, the nearby data is there when needed. Perhaps more importantly, when we load a value, and then need it again a short time later, it's already in the cache.
Caches, perhaps more than any other transparent hardware feature, can have a huge effect on program performance. If your program reads through an array of bytes in order of increasing address, the cache helps. But if your program reads through the array in pseudorandom order, the cache can offer much less help.
int A[MAX]
i=0; while (i<MAX) {A[i]=0; i++;}
i=0; while (i<MAX) {A[i]=0; i+= J; if (i>MAX)
i=i-MAX;} // J relatively prime to
MAX
[Wednesday 1/16]
At this point we'll return to BOH3 Chapter 1, the "hello world" program in C. Here's the basic program:
#include <stdio.h>
int main() {
printf("hello, world!\n");
return 0;
}
We can (on a linux system) compile this with gcc hello.c. The executable is then in a.out; alternatively, we can compile it with gcc -o hello hello.c to leave the executable in file hello. On unix-based systems there is generally no .exe filename extension.
We then run the command with ./hello. The ./ simply refers to the current directory, as in "run the command hello in the current directory. For security reasons, running commands in the current directory is not the default, hence the need for the ./.
The file hello is in ELF format ("executable and linkable format"). We can find out a little about the "sections" of this file with objdump -h hello or readelf -S hello (or the -a option for everything).
Why is there so much stuff in this file?
The transformation from hello.c to hello can be broken down into substeps:
This is the part of the computer that takes care of booting up, managing programs, and managing I/O. (Managing the screen may or may not be an operating-system-level task.)
One task of the OS is managing virtual memory, which we'll get to later.
Another part handles processes. When we run hello, a process is created. The process is laid out in memory something like this:
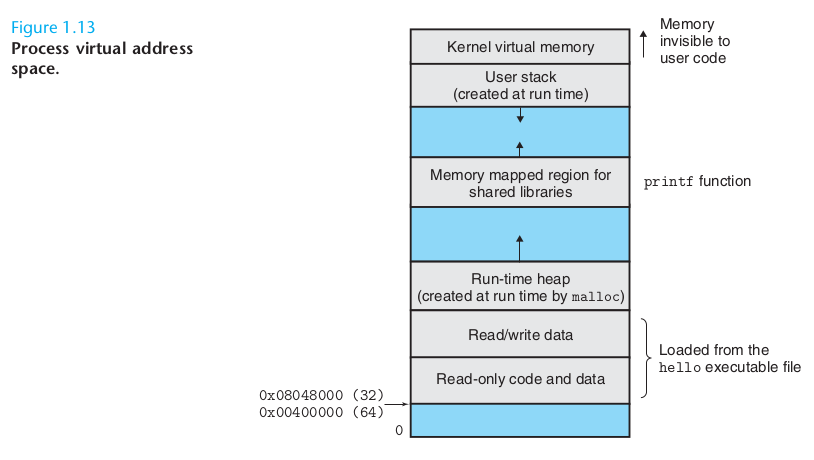
After being loaded into memory, the process starts executing. Where is "hello" kept?
Files are, essentially, named streams of bytes (some operating systems allow higher-level structures than bytes; others take the approach that there is no particular benefit to this). We can open a file, which looks up the file's name in the filesystem and finds where on the disk the data is stored. We can then read from the file, or write to it.
There are many different designs for filesystems. We will eventually look at a few of them.
Modern CPUs typically have multiple cores; that is, multiple independent sub-CPUs, each with cache, a register file and an ALU. Here is a diagram from BOH:
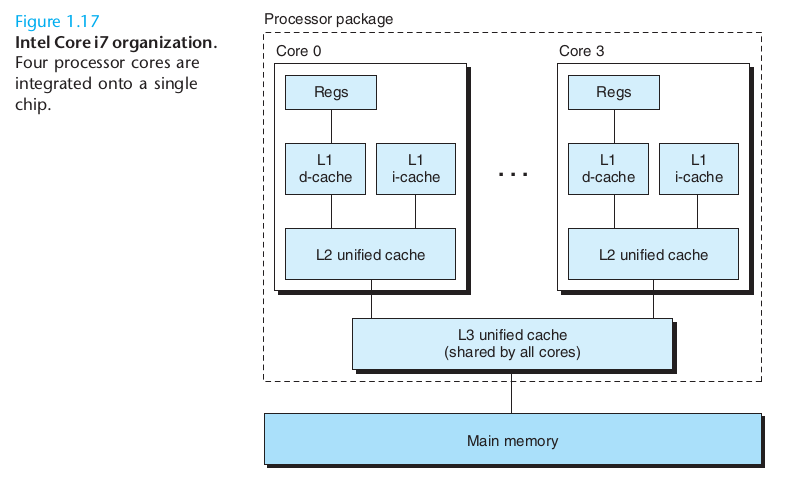
The L1 d-cache is for data, while the i-cache is for instructions. The latter is read-only, mostly, making it simpler. It is not immediately clear why each core needs both an L1 cache and an L2 cache. One reason is that the L1 cache is faster. The table below indicates the fetch time, in clock cycles, for a typical Intel CPU:
| cache |
access, cycles |
size |
| L1 |
4 |
32 KB |
| L2 |
11 |
256 KB |
| L3 |
30-40 |
8192 KB |
Another advantage of a separate L1 cache is that with a separate i-cache, the i-cache never has to deal with cache-line replacement in a small loop due to data loads and stores.
The typical block size for L1, L2 and L3 caches is 64 bytes.
On newer Intel processors, all three caches are on the CPU chip; in days of yore, there was often an external cache chip.
With multiple cores, there can be multiple threads executing in parallel. These threads can either use shared memory (which means their caches must be consistent) or separate memory.
Transitioning from one thread to another can be slow. But hyperthreading, in which each core keeps separate registers (and maybe even a separate L1 cache) for each thread, allows very fast thread switching. It can even be fast enough that a core can switch to another thread while the first thread is waiting for data to be loaded from DRAM.
A practical problem for programmers is thread synchronization. When a thread wants to write some data to shared memory, it must ensure that some other thread won't be writing at the same time. At other points, sometimes one thread must wait for another thread to complete, before it can continue.
The classic data type is the 32-bit int, from the early days of C. There are also 16-bit short ints, or shorts, and 64-bit longs. Even on most 64-bit systems, an int is 32 bits. Java inherited all this.
It is convenient to describe bytes and words and ints using hexadecimal, or base 16. One hex digit, 0 1 2 3 4 5 6 7 8 9 a b c d e f, represents 4 bits. Two hex digits make up a byte, and eight make up an int.
0x4a = 4*16 + 10 = 74
0xff = 15*16 + 15 = 255
Hex calculators
big-endian and wrong-endian
2's-complement
C: see c.html